前言
下面我们来看一看sql优化的一些东西。
sql优化
插入数据
插入数据的sql就是insert语句,其优化策略一般是将多次插入改为批量插入,这样可以减少IO的次数。
批量插入数据
例如,如果我们要插入三条数据,可以这样写
|
|
这种方式每次都要进行磁盘IO的连接和读写,可以使用批量插入来减少磁盘IO的读写
|
|
手动提交事务
在默认情况下事务是自动执行的,基本上是每执行一条更新操作就会去提交事务。而频繁的事务提交也是会影响性能的。因此,我们可以以手动提交事务的方式来减少事务的提交。
|
|
主键顺序插入
我们假设主键值是自增的id,那么,什么是主键顺序插入呢?
|
|
也就是说,按照顺序插入可以减少数据库底层数据结构的调整。
使用load而不是insert
当数据量特别大时,例如,一次性插入几百万条的记录,就应该使用load命令
|
|
数据之间使用,进行分隔,每一行之间使用换行作为结尾。
深分页优化
在项目中,对数据进行分页优化是很有用的,假设这里有几十万条数据,那么,我们在做分页查询时,其sql可能如下
|
|
这个意思是说,取出前十条数据,然后返回前10条数据。当数据量很大时,sql查询看起来像是下面的这样
|
|
也就是说,取出前100010条数据,然后返回100000到100010中间的数据。
一种优化办法是去使用索引。
首先查出分页数据对应的id
|
|
由于id是具有主键索引的,所以查询效率很快。
然后再根据id来进行查询,也就是子查询
|
|
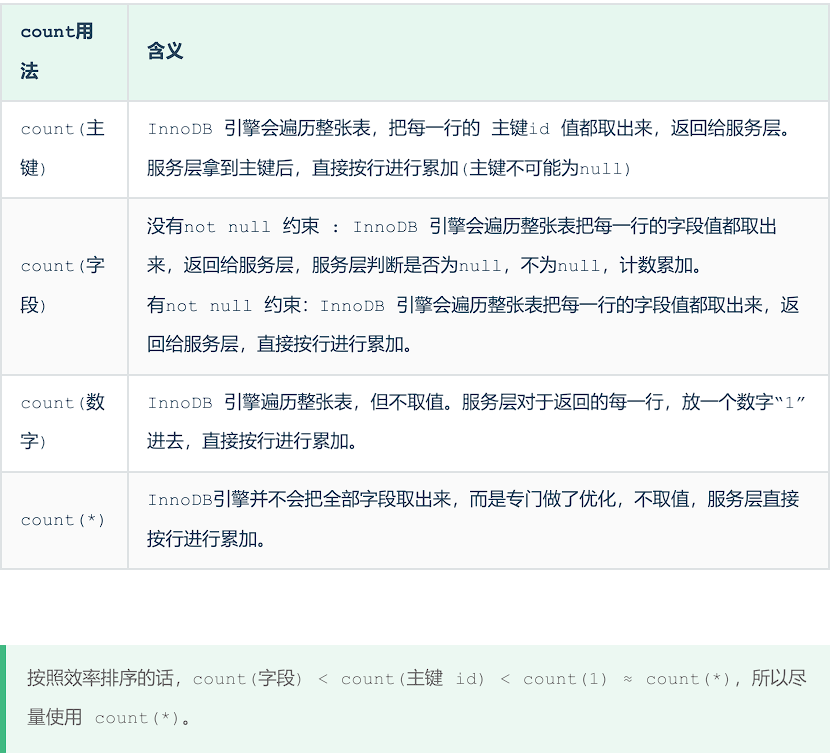
count优化
update优化
update语句一般与where筛选一起使用,所以,从查询的角度出发,查询时使用索引可以加快查找。
而且,由于InnoDB支持行级锁,即单条数据,但是行锁是针对索引的锁,行锁未启用就会升级为表锁。
在使用id进行查询更新时,使用的是行级锁
|
|
事务提交后,行锁释放。
使用非索引字段进行查询时,使用的是表级锁。
|
|
InnoDB的行锁是针对索引加的锁,不是针对记录加的锁,并且该索引不可以失效,否则会从行锁升级为表锁
锁
下面来说记录一下mysql中的锁,这一部分也是非常重要的知识。
全局锁
全局锁是对整个数据库进行加锁,加锁之后整个实例就只处于只读状态,后续的写操作都会被阻塞。
其典型的应用场景就是做全库的逻辑备份,对所有的表进行锁定,进而保证数据的一致性和完整性。
加全局锁
|
|
释放锁
|
|
表级锁
每次操作都锁住整张表,锁的粒度大,发生锁冲突的概率最高,并发程度最低。对于表级锁,主要分为以下三类
- 表锁
- 元数据锁(
meta data lock) - 意向锁
表锁
表锁其实就是一种读写锁,读的时候可以多个线程共享的去读,写的时候只能有一个线程在写。而且读写锁之间是互斥的,即读的时候会阻塞写操作,写的时候会阻塞读操作。
加表锁
可以给这张表加上read lock或者write lock
|
|
释放表锁
释放的时候需要使用关键字unlock
|
|
元数据锁
meta data lock,这个锁是mysql底层为了保证数据的完整性而自带的一种结构。它无需我们手动添加。
其实元数据锁就是读写锁的一种,可以分为
shared_read_only和shared_no_read_write,即对一张表的数据只可以并发读或排他的写,对应于上述提到的表锁shared_read,表层级的并发读shared_write,表层级的并发写exclusive,表层级的大锁,即这种sql语句可能会改变表的结构。
主要的,对于表而不是行数据,此类锁基本上分为改变表结构的锁和不改变表结构的锁。
改变表结构的sql语句是
|
|
在执行此类语句的时候,其它线程都不可以进行读写操作。
对应的,像不改变表结构的读
|
|
对应的,不改变表结构的写
|
|
这些语句可以并发的写
并发写 在 MDL(元数据锁) 的语境下,不是指两个线程同时修改同一行数据,而是指多个线程可以同时修改同一张表中的不同数据行,只要不涉及结构(DDL)更改,就不会互相阻塞。
意向锁
意向锁是为了避免行级锁和表级锁产生冲突的一个快速检测方案。
当事务要对某些行加锁时(比如
SELECT ... FOR UPDATE),InnoDB 会自动在表级别加一个“意向锁”(IS或IX)来声明: “我打算锁住这张表的某些行”。
对于行级锁来说,其锁住的是某一行数据,此时,如果我们需要添加表锁,那么就得一行一行的去进行遍历,知道找到被加锁的行为止。
当数据规模较小的时候,这样的方案可以接受,但是当数据规模过大,那么这样的操作就是一个耗时操作。
所以,mysql的解决方案是,在添加行锁的时候就添加一个意向锁,这样就不需要进行耗时检测。
只要理解了意向锁是行锁引起的,那么就好理解意向共享锁和意向排他锁。
- 意向共享锁: 与表锁的读锁兼容,与写锁互斥
- 意向排他锁:与表锁共享锁和排他锁都互斥
行级锁
行级锁,每次锁住对应的行数据。锁定粒度最小,发生锁冲突的概率最低,并发程度最高。行级锁主要分为下面三个
-
行锁:锁定单行记录的锁,防止其它事务对此进行
update和delete,在RC RR隔离级别下都支持。
-
间隙锁:锁定索引记录间隙,确保索引间隙不变,防止其它事务对这个间隙进行
insert,产生幻读。在RR隔离级别下支持
-
临键锁
行锁和间隙锁的组合,锁住数据同时锁住前面的间隙
Gap,在RR隔离级别下支持
行锁
行锁里面可以分为共享锁和排他锁,其实也就还是读写锁。
需要注意的一点是,无索引行锁升级为表锁。行锁针对是索引,如果字段没有索引的话,行锁就会升级为表锁。
间隙锁&临健锁
默认情况下,InnoDB在RR事务隔离级别允许,InnoDB使用next-key锁进行搜索和索引扫描,防止幻读。
总结
下次来看看还有哪些比较难的机制!