前言
这次继续来写补全计划。
表设计原则
很多情况下,在开发业务时就需要制定好表的格式,一般来说,各个表之间也存在着各种各样的联系,基本可以分为
- 一对一结构
- 一对多或者多对一
- 多对多
一对多结构
一对多结构是很常见的一种关系,例如,一个部门会有很多个员工,而一个员工一般只属于一个部门。
对于这种关系来说,一般是设计两张表,一张是员工表,另一张是部门表,其中,在“多的一方”(一对多的多)建立外键,指向“一”的主键(外键必须是unique或者primary key)
多对多的关系
- 学生与课程的关系
- 一个学生可以选修多门课程,一个课程也可被多个学生选择
- 建立第三张中间表,中间表至少包含两个外键,关联两方的主键。
例如,将学生表和课程表的学生id字段和课程表的id字段抽取出来,组合为一张新的表。当学生需要休学时,这个学期的课表就被设置为空;同理,当选课学生过少时,也可以把这门课给取消
一对一的关系
一对一关系一般多见于像用户基本信息的表种,一般的,用户个人信息有很多,像年龄,身高、体重;像学历水平、毕业院校、毕业时间等。如果把这些用户信息全部存在一起,会导致使用时不够灵活。可以使用以下的方法。
将用户个人信息进行拆分,个人信息可以分为:用户基本信息、用户教育信息、用户家庭信息等。我们只需要在用户教育信息和用户家人信息中新增用户基本信息的一个主键即可。
多表查询
多表查询可以分为连接查询和子查询两类。
连接查询
内连接
内连接是查询两张表的公共部分,也就是交集部分。这里有两种语法,我们还以员工和部门表来作为案例演示一下。
例如,我们希望查询员工的个人信息和员工的部门,员工表只有部门表的一个外键,所以只查询员工表是无法查询出员工所属的部门,必须对两张表进行联合查询才可以。
-
隐式内连接
1select 字段 from 表1, 表2 where ....; -
显式内连接
1select 字段 from 表1 [inner] join 表2 on 连接条件例如,使用内连接查询员工的姓名和部门
1select e.name, d.name from emp as e join dept as d on e.dept_id = d.id;
外连接
外连接包括左外连接和右外连接。左外连接查询左表所有的数据,右外连接查询右表所有的数据。
之所以分左右,是因为在有些情境下,我们需要查询在左表中出现了但是有表中没有出现的内容。左右连接之间可以相互转换。
子查询
子查询的含义是将查询结果进行进一步筛选后可以将查询的结果作为数据源进行筛选。子查询的使用比较灵活,但是效率不高,这里不在详细展开讲解。
事务
事务(transaction)是一组操作的集合,对于事务来说,也就是这一组操作,要么同时成功执行,要么就是失败执行,不存在事务中的事务有些执行成功了,有些执行失败了的情况。
查看事务/设置事务的提交方式
这里有一个全局设置@@autocommit,对于事务来说,默认是自动提交的
|
|
我们把这个变量设置为0,这样事务就会变为手动提交
|
|
此时,如果要进行更新删除操作,必须要手动提交事务才会更新到数据库。
提交事务
|
|
回滚事务
|
|
开启事务
开启事务的意思是,执行开启事务代码后,此后一系列的更新操作必须要提交事务后才可以更新。
|
|
上面两行代码都可以开启事务
事务四大特性
ACID
A:Atomicity,原子性,事务是不可分割的最小执行单元,不存在中间态C:Consistency,一致性,事务完成后,所有的数据都是一致状态I:Isolation: 隔离性,事务不受外界并发操作的影响D:Durability: 持久性,事务提交或回滚后,它对数据库中的数据改变就是永久的
并发事务问题
这是指事务不同的隔离等级所导致的,这个时候就会引起各种各样奇怪的读问题
脏读/read uncommit
脏读的意思是读到了未提交事务的数据。例如,在并发操作下,这里有一个变量money,假设此时余额是100,对于A来说,他消费了50元,此时数据还未提交。这个时候,B也来进行消费了,他想要消费100元,由于此时的事务隔离级别是read uncommit,此时B发现只剩50元,所以操作失败。
如果A操作成功的话,那么B这样做实际上是没有问题的,但是假设银行服务器出现了波动,那么A事务操作失败,就要发生回滚,也就是说,此时A消费失败,B可以进行消费,但是B读到了未提交的数据,造成消费失败。
不可重复读/ read commit
不可重复读的意思是,在一个事务中,前后两次读到的同一个变量的值不相同。这是很有可能发生的,也就是说,事务A可以读到事务B对同一变量的修改。实际上这样做是有很大问题的。
幻读 / repetable read
幻读的意思是,第一次读的时候发现某某数据不存在,然后插入数据时又发现数据存在了,像是幻觉一样。
思考一种常见,假设A要插入一条员工信息,插入时先查看一下是否存在该用户,发现不存在,这个时候B插入了这条信息,此时A再插入,发现已经存在了。
其实,调整隔离级别就可以避免这些问题。
隔离级别
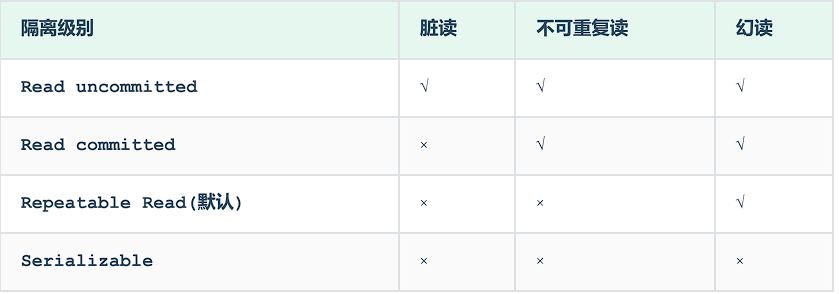
对于这些隔离级别来说,从上往下,数据库的并发能力越差,性能也就越差,但是解决的问题也越多。
查看隔离级别
可以查看当前数据库的隔离级别
|
|
可以看到,默认情况下,mysql使用的数据库隔离级别是
|
|
可重复读,也就是说,可以解决脏读和不可重复读问题。
修改隔离级别
|
|
此时再查看一下当前数据库的隔离级别
|
|
注意,这只是当前session的所有数据库隔离级别,如果要以后永久修改的话,可以使用global
|
|
总结
基础2就是这样了,下面是进阶内容!