学习率
学习率是一个很重要的参数,而且学习率决定了网络能否快速的收敛并趋于稳定。目前为止,我们接触到的网络实际上都是一个优化问题,即如何找到损失函数的极小值。对于多元函数使用的就是梯度下降法去找到极小值,其中又有很多梯度下降的优化版本,例如sgd + momentum、adam等方法,这些方法里面都要用到学习率这个参数
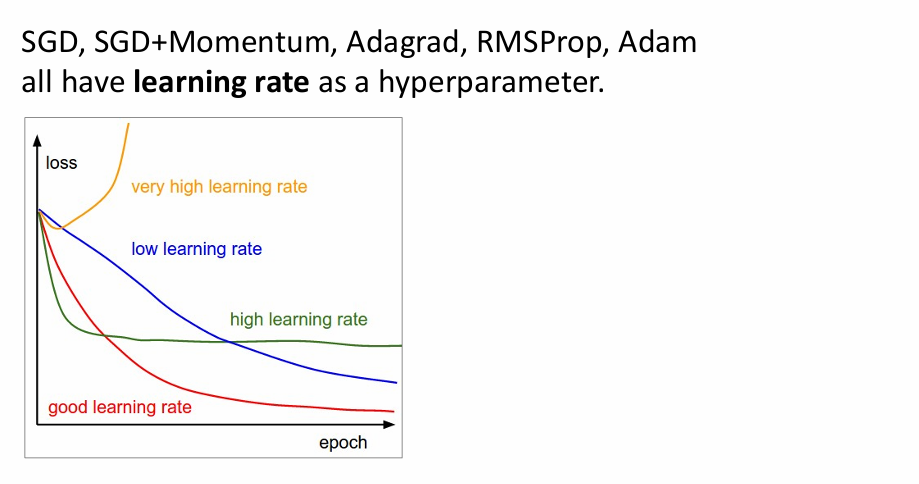
老师给出了许多学习率的选择方法
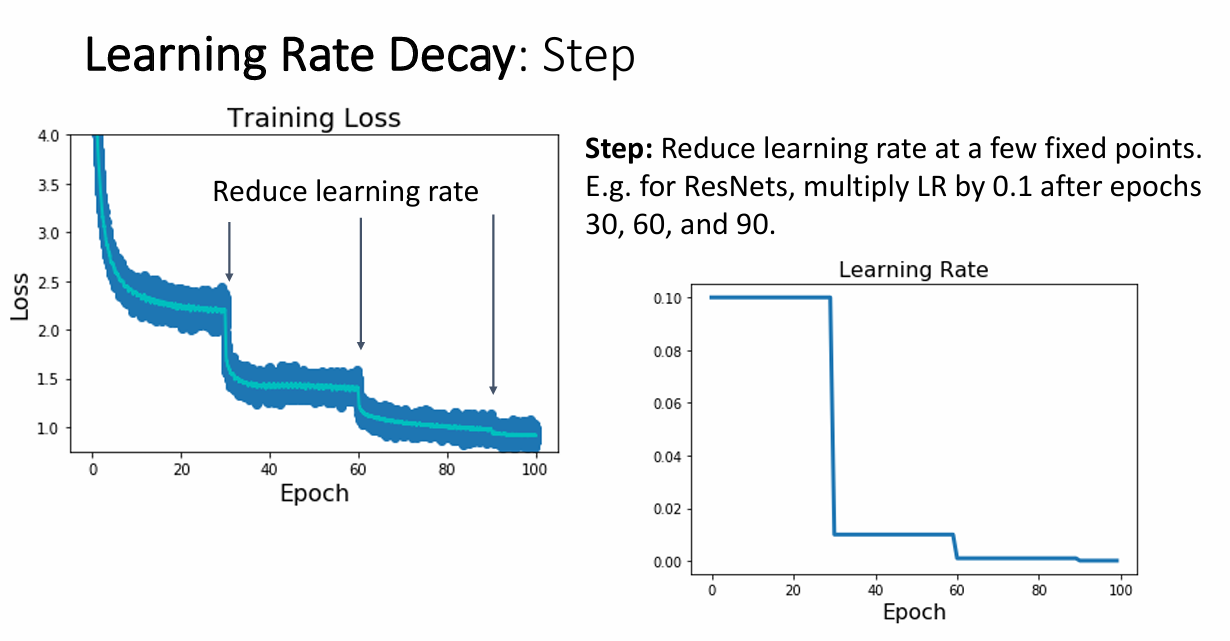
step 学习率
step学习率的思路就是每经过给定的几个epochs,就重新设置学习率。可以这样做是因为在学习初期,即使学习率很大也没有关系,大的学习率反而可以减少训练时间,当经过几轮epoch后,把学习率降低可以减少模型的震荡,从而提高精度。
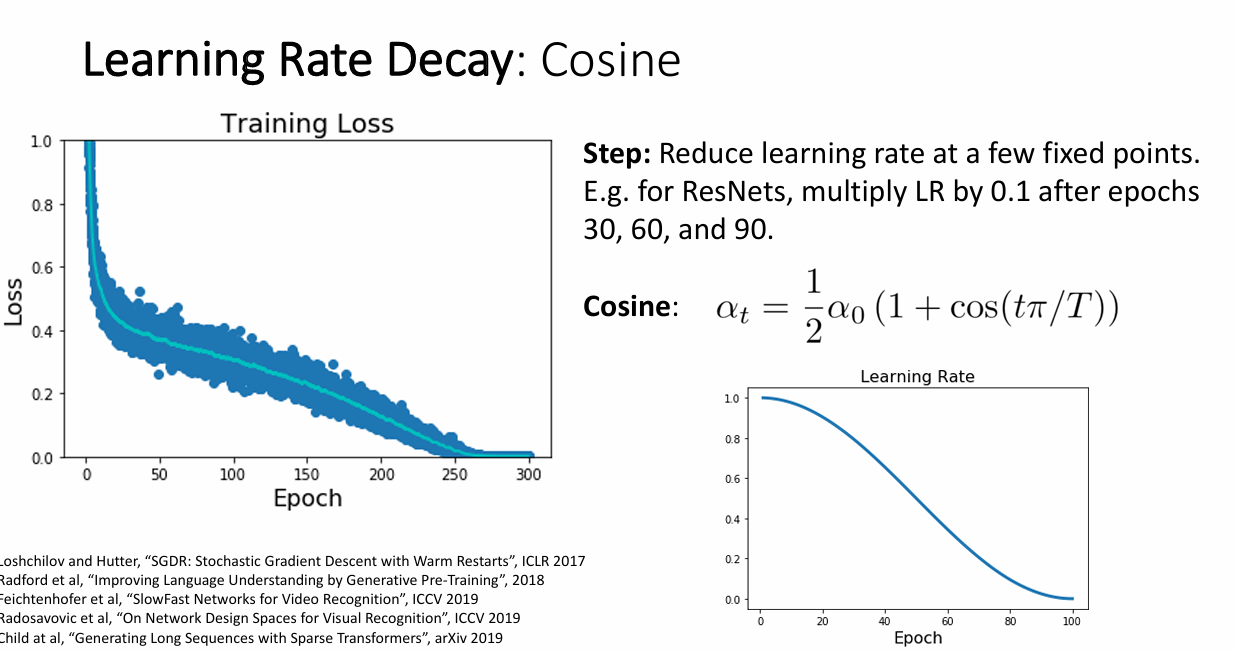
cos 学习率
在训练过程中,学习率的参数变化是cos型的
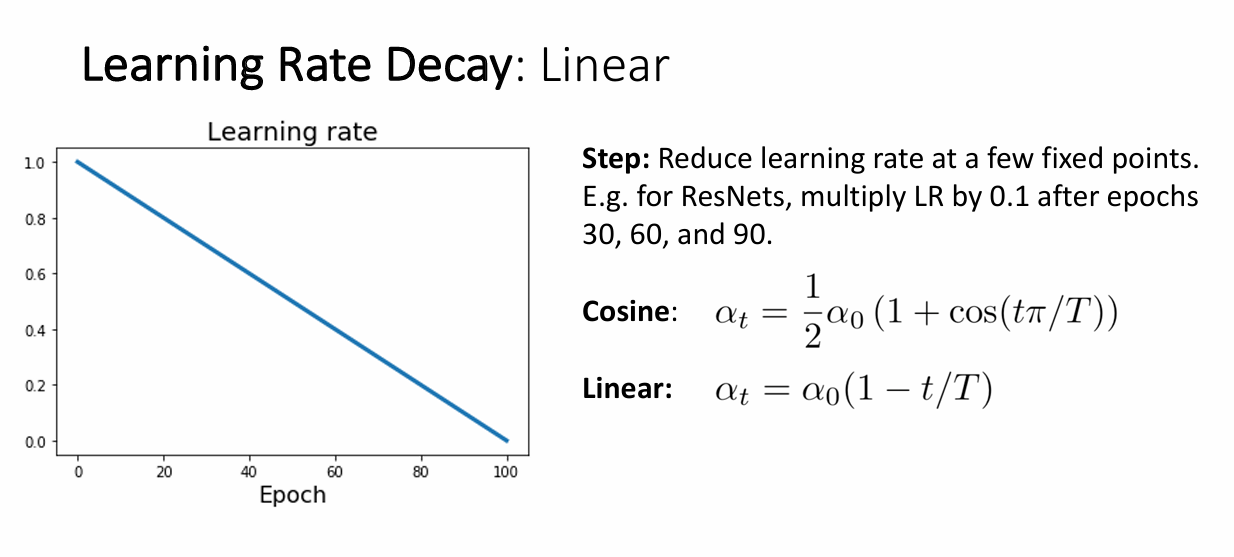
线性下降学习率
学习率的选择是线性的
平方根学习率
这个图片是反平方根的函数曲线….

超参数选择
选择超参数(hyperparameter)是深度学习和机器学习中关键的步骤,影响模型的性能和训练效率。
1. 检查初始损失 (Check initial loss)
- 目的:确认模型和数据管道是否正确配置。
- 细节
- 使用默认或初始超参数(如随机初始化权重,标准学习率)。
- 检查初始损失是否异常高或为NaN。
- 如果损失值异常,可能是数据预处理或模型设置的问题。
2. 在小样本上过拟合 (Overfit a small sample)
- 目的:验证模型是否有能力拟合数据(模型复杂度是否足够)。
- 细节
- 使用数据集中的一小部分样本(例如5-10个)。
- 调整模型直到它能够完全拟合这组数据,损失降到接近零。
- 如果无法过拟合,检查模型架构或超参数(如学习率、网络深度等)。
3. 找到能使损失下降的学习率 (Find LR that makes loss go down)
- 目的:找到一个合适的学习率,使损失能稳步下降。
- 细节
- 采用 learning rate finder 技术。
- 逐步增加学习率,绘制损失随学习率变化的曲线。
- 选择损失开始明显下降但未发生震荡的学习率(通常在曲线的下降初期)。
4. 粗略网格搜索,训练1-5个epoch (Coarse grid, train for ~1-5 epochs)
- 目的:快速筛选出表现较好的超参数范围。
- 细节
- 在关键超参数(如学习率、权重衰减、batch size)上进行粗粒度的网格搜索。
- 每次试验只训练1到5个epoch,足够观察趋势但不过多浪费计算资源。
- 排除性能较差的参数组合。
5. 精细网格搜索,延长训练时间 (Refine grid, train longer)
-
目的:进一步优化超参数,找到最佳的参数组合。
-
细节
- 缩小关键超参数的搜索范围,进行更精细的网格搜索。
- 增加训练epoch(例如10到50个)以评估长期性能。
- 检查模型在验证集上的表现以避免过拟合。
6. 检查学习曲线 (Look at learning curves)
-
目的:通过学习曲线分析模型的训练动态。
-
细节
-
学习曲线显示训练和验证损失或精度随时间变化的趋势。
-
常见问题及解决办法
- 如果验证损失明显高于训练损失:模型可能过拟合,需要正则化或增加数据。
- 如果两者都较高:可能是学习率太低或模型复杂度不足。
- 如果训练损失震荡:可能是学习率过高或模型过于复杂。
-
这也是老师在课上提到的这几点,为了方便查看训练的进展,一个很好的习惯是把模型在测试集上的精确度和验证集上的精确度给可视化,老师这里提到了一些有用的建议。
-
loss一开始不降低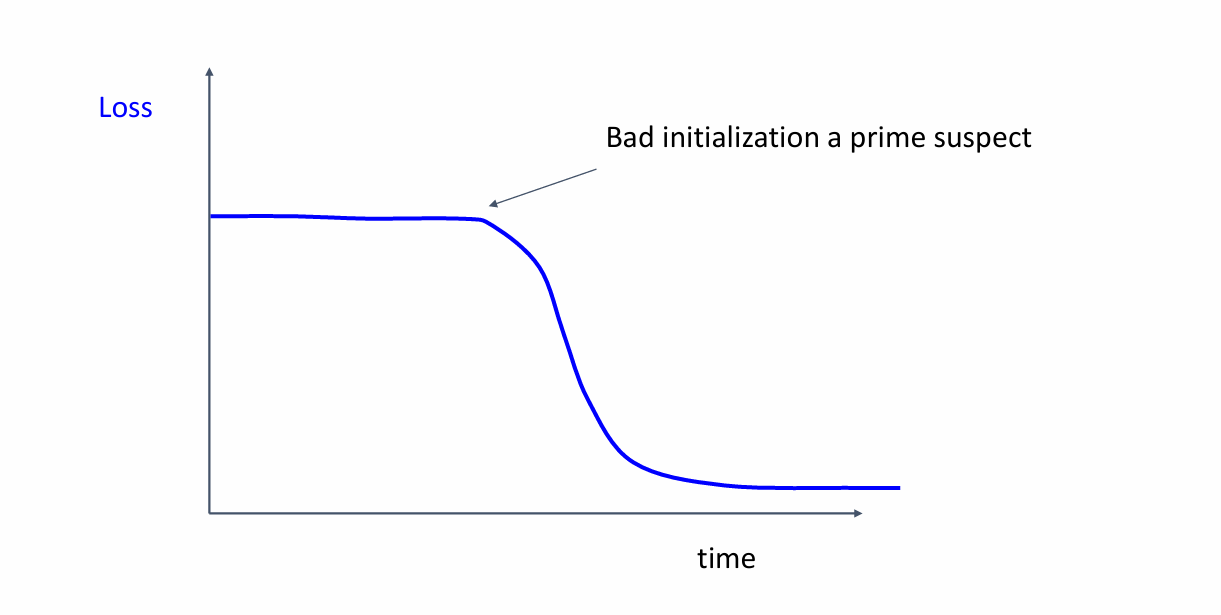
你的初始化很bad!
-
loss很高而且随着训练的进行不发生变化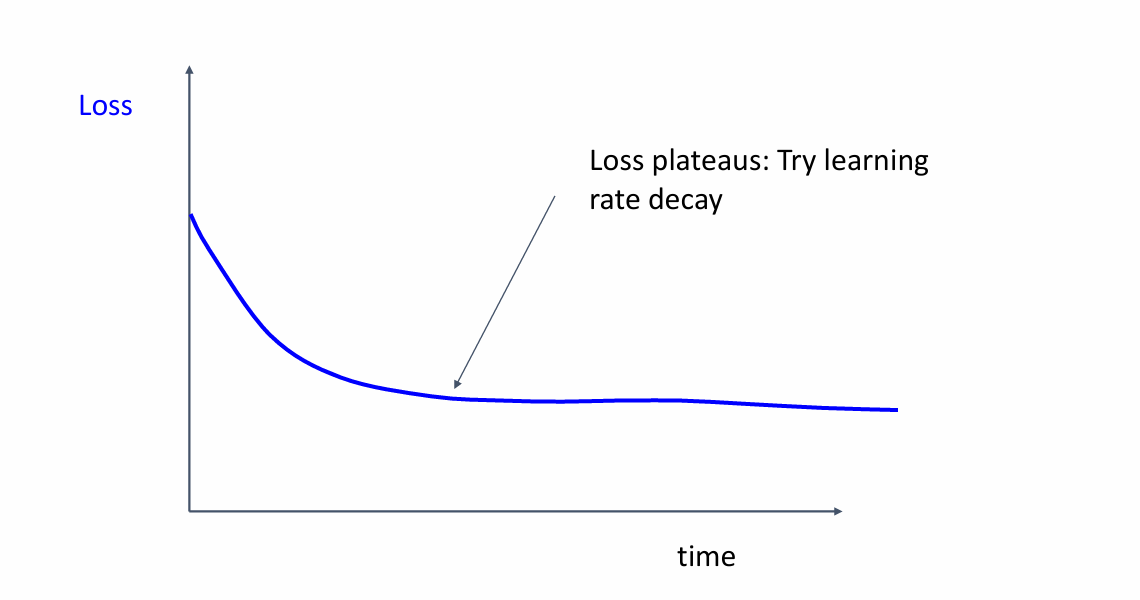
学习率太大了,试试学习率衰减的办法吧!
-
衰减的太早了,导致不能快速下降
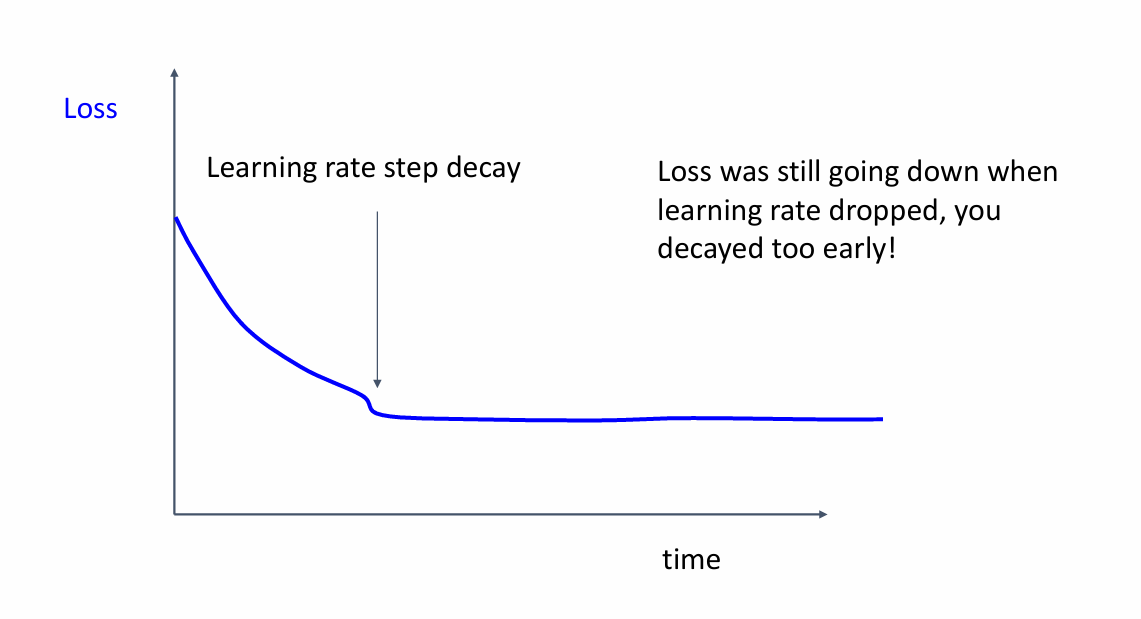
-
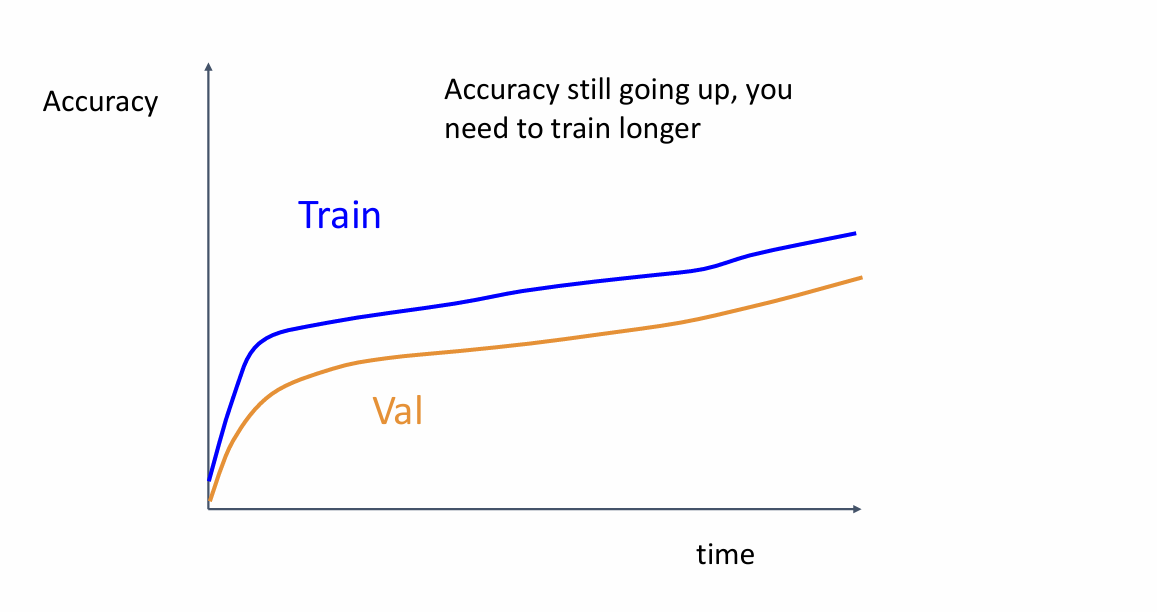
准确率依旧在上升,应该训练更长的时间
-
这种情况也是很常见的,即数据在训练集上精度很高,但是在测试集上精度却不增高,这是因为发生了过拟合,导致模型只能很好的识别出“见到”过的数据
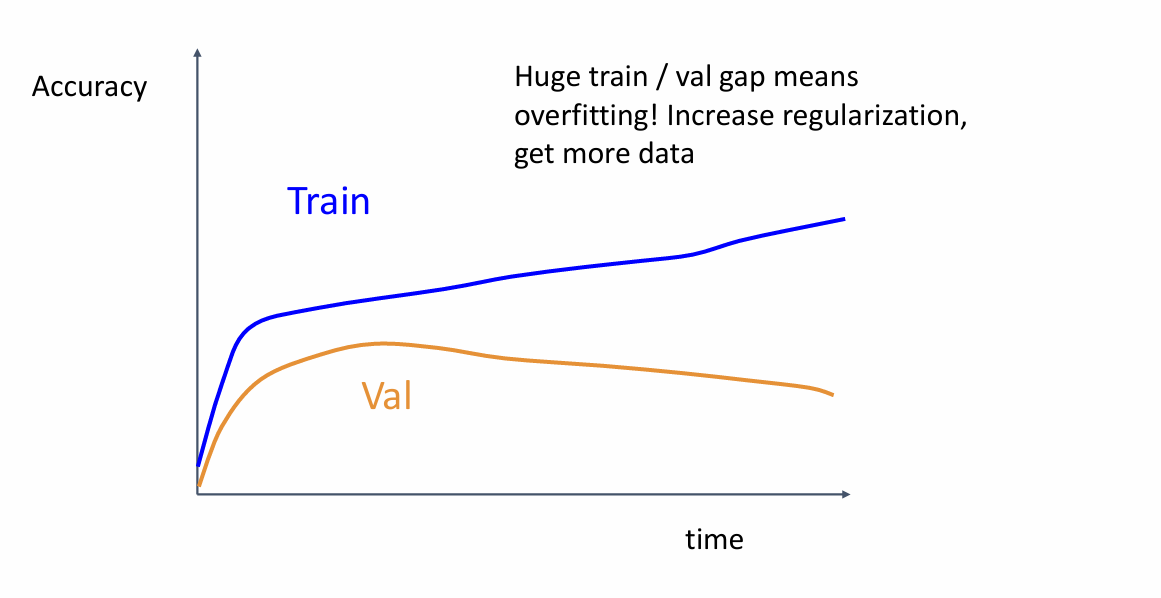
-
训练集与验证集之间精度在训练过程中相差很小,假设数据来源可靠的话,那么说明模型还不够复杂,或者模型还是处于欠拟合的状态

总结
在这一部分,我们只介绍了学习率以及超参数选择的一些技巧,后面的内容与迁移学习以后再做总结!