前言
计算机视觉的任务大概有下面这些:
- 图片分类
- 语义分割
- 物体检测
- 实例分割
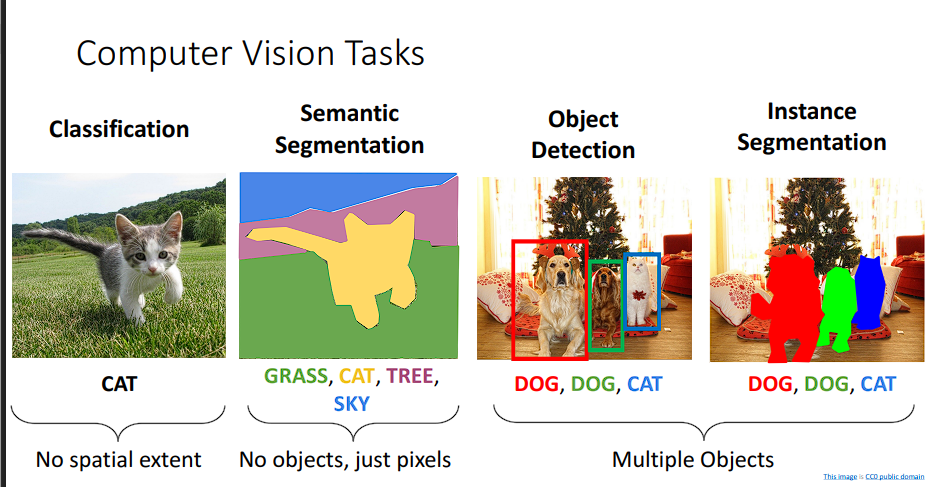
在之前的任务中,我们已经认识了图片分类任务,即使用经典的卷积神经网络去对图片进行分类,今天我们来看看目标检测。
目标检测
首先来给目标检测定义一下,其输入是一张RGB图片,输出是图片中物体的类别标签和一个边框,就像图片中的那样

所面临的挑战
首先,这次输出不再是单一的标签,而是多个输出,包括图片上每个物体的类别和一个边框。其次,我们不再只有一种输出,而是有一个"类别标签"和“边框”。最后,输入通常是非常大的像素图片。

不过我们来看看几种常见的解决办法
检测单一物体
对于输入图片只有一类物体的情况,其实多做的一部分只有“边框”,这个时候我们可以用一个联合Loss
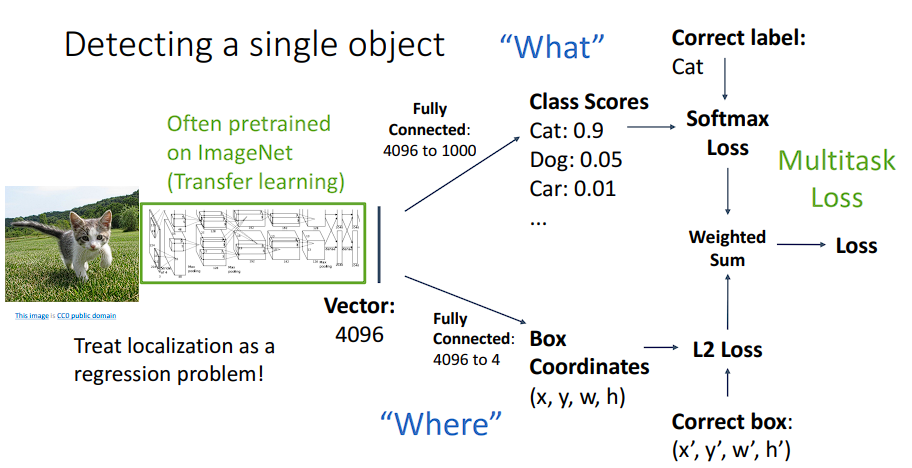
即输出一个框和标签,最后对最小化他们的Loss和,这个方法也被叫做多任务损失。问题是,当图片中的图片数量种类变多后就变得不可量化了。因为网络实际上只会输出一个标签和一个边框,所以我们需要改进网络。
滑动窗口改进
一个很简单的思路是去使用滑动窗口去动态采样一张图片,即每次动态取样一张图片,确保一张图片内只有一个物体和一个边框,这样我们就可以使用之前的CNN和联合损失来进行训练。可惜的是,滑动窗口的大小、窗口的步长都是未知的参数,而且,在滑动窗口采样的过程中,会存在有数量巨大的图片,这会使得网络的输入变得巨大,从而更难采样。

区域提议
虽然滑动窗口的想法很好,但是缺点就是计算量太大,一个很好的思路是:每次使用算法去计算一些“高质量”的小方框,这个算法后来又有一系列的工作,总的来说就是去使用算法去快速生成一些候选框。

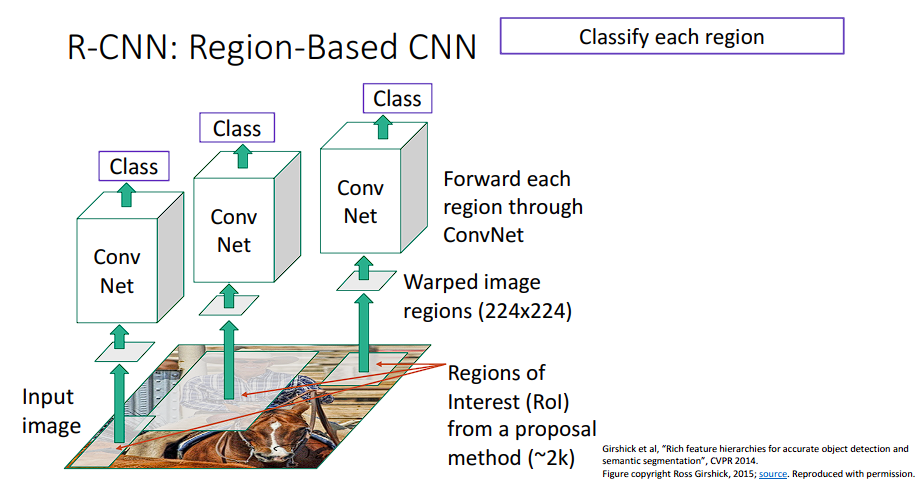
R-CNN
R-CNN的核心思路就是Region + CNN。
Regions:使用Selective Search快速生成2000个候选框,也就是我们上文提到的Region ProposalCNN:使用CNN对每个候选框提取特征
把候选框缩放为
224x224的大小,方便卷积分类
这个时候就完成对候选框内的图片分类了,还需要调整矩形框的位置。简单来说,我们会使用回归预测让模型输出一个微调参数,缩放调整框的大小
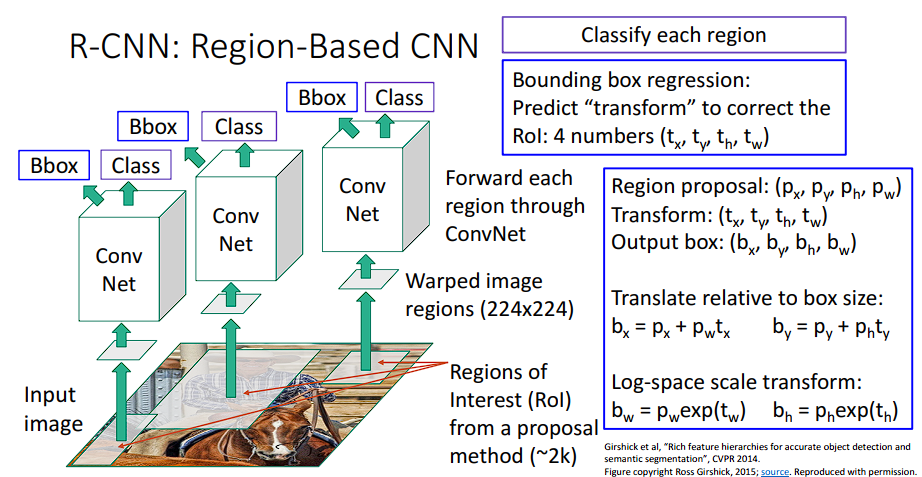
最后将网络的框与真实的框进行比较。其中,怎么衡量预测框和真实框之间有多像呢?
IoU
IoU即,Intersection over Union(交并比),即$$ IoU = \frac{预测框 \cap 真实框}{预测框 \cup 真实框}$$

图片左下角说明了这个分数的范围,即越大越好。
非极大值抑制
在做目标检测的时候,经常会遇到"一个物体会被检测出多个框"的问题,我们只需要其中的一个,这个时候我们可以使用NMS,即非极大值抑制,其算法流程如下:
- 找到最高得分的边框
- 把与得分最高边框,即
IoU > threshold的其他边框消除掉 - 如果还有其它边框,继续第一步,直到剩下最高分的边框为止

例如,上图中蓝色和橙色边框的IoU分数较大,那么就消除橙色的边框。这个思路很好,缺点在于,当图片中有两个重叠程度较高的物体时,NMS可能会消除掉效果好的边框

mAP评估
以下总结来自AI
Mean Average Precision (mAP,平均精度均值) 是计算机视觉中用于评估目标检测(如YOLO, SSD)和实例分割模型性能的核心指标。它综合了不同类别模型的精确定位(IoU)和分类能力,通过计算所有类别的平均精度(AP)来衡量模型在真实场景中的稳健性,分数越接近1表示模型越完美。
关键概念与核心组件
IoU (交并比 - Intersection over Union): 衡量预测框与真实框(Ground Truth)的重叠程度。通常设定一个阈值(如0.5),高于该阈值则认为检测正确(TP),否则为假正例(FP)。
Precision (精确率 - P): 模型检测为正的样本中,真正正确的比例。
Recall (召回率 - R): 实际为正的样本中,被模型正确检测出来的比例。
AP (Average Precision - 平均精度): 单个类别的PR曲线(Precision-Recall curve)下的面积。它代表了在不同置信度阈值下模型对该类别的综合性能。
mAP (Mean Average Precision - 平均精度均值): 对所有类别的AP值取平均值。
mAP 的计算步骤
排序: 将模型对所有图片的某个类别的检测结果按照置信度得分(Confidence Score)从高到低排序。
计算PR曲线: 计算不同排序位置的P和R值,绘制PR曲线。
计算AP: 计算该类别的PR曲线下的面积。
计算mAP: 将所有类别的AP值取平均值。
常见指标变体
mAP@0.5: IoU 阈值设定为 0.5 时计算的 mAP(Pascal VOC竞赛标准)。
mAP@0.5:0.95: 在不同 IoU 阈值(0.5, 0.55, …, 0.95)下计算 mAP 后取平均,这是 COCO 数据集使用的更严格的评估标准。
总结:mAP 是一个单一的、量化的分数,能够全面反映模型在多个类别、不同目标位置和大小下的综合检测能力。
具体计算细节以后再看,先知道有这个东西。
Fast-R-CNN
让我们再来分析一下R-CNN的计算过程,来分析一下为什么它比较慢。首先,我们需要抽取将近2000张候选框,对于这2000张候选框来说,都得计算他们的一个卷积结果。但是,候选框中有很多区域都重叠的,也就是有些像素是被重复计算很多次的。一个很明显的直觉是,我们可以让整张图片先去做卷积,然后再根据候选框来选择对应的特征图,这样就不用重复计算卷积了。
大概计算结果如下:
-
R-CNN1图像 → Selective Search → 2000个框 → 各自Crop/Warp → 各自CNN → 特征 → SVM分类 → BBox回归 -
Fast R-CNN1 2 3图像 → CNN → 特征图 → 对2000个框做RoI Pooling → 各自RoI特征 → 全连接层 → 同时分类+回归 ↑ Selective Search (仍需要,但只在CPU上跑几毫秒)
下面我们来说一说其详细的计算过程
Backbone
Backbone是模型的“特征抽取器”或者说“主干网络”,比如说,可以使用AlexNet、ResNet等。用于目标检测时,需要对网络进行改造,比如:
- 移除末尾的分类输出,不要最后的全连接层等
- 保留卷积层,使用卷积特征图作为输出
- 特征抽取
区域映射
为了继续确定候选框里面的像素,我们需要以某种缩放运算将缩放前候选框的坐标调整到特征图对应的部分,然后使用池化去抽取每个RoI的特征,最后输出到全连接层上进行分类。
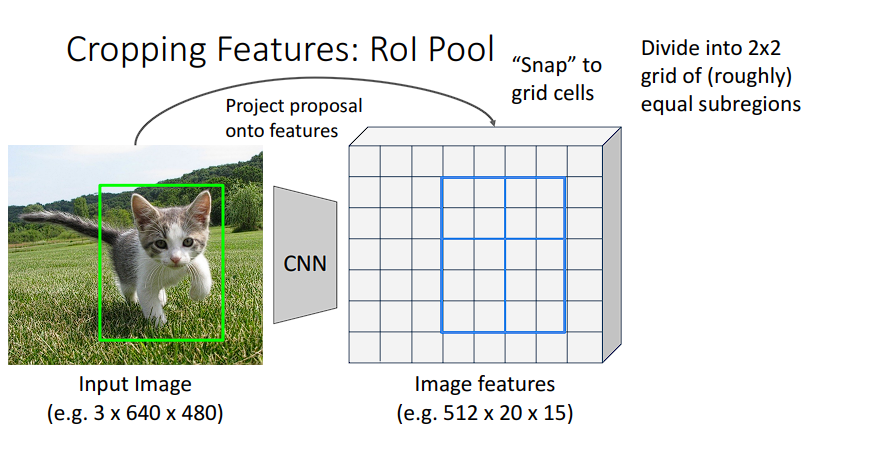
全连接层的输入是固定的(比如7x7),而我们现在有2000个大小不同的候选框,映射到特征图上也是2000个大小不一的特征图,而RoI Pooling就是一个把映射后的特征图也可以继续输入到全连接层的压缩机。
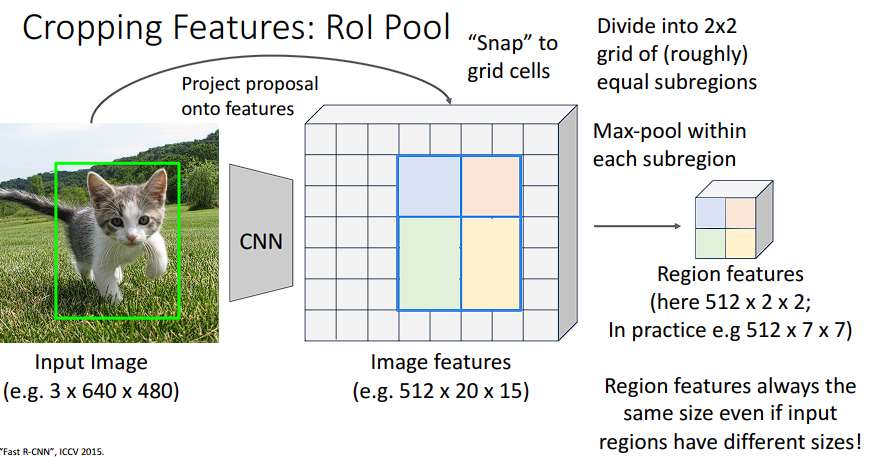
也就是说,候选框在经过投影之后,我们需要将网格给动态池化,强行把这个区域划分为7x7=49的格子,然后找到每个格子的最大值,得到一个像素,最后输出7x7的特征块。
缺点
上述过程中有两次取整:
- 坐标映射取证:候选框在特征图上的坐标需要取整
- 网格划分取整:每个小格子也不是对齐的,可能导致检测误差
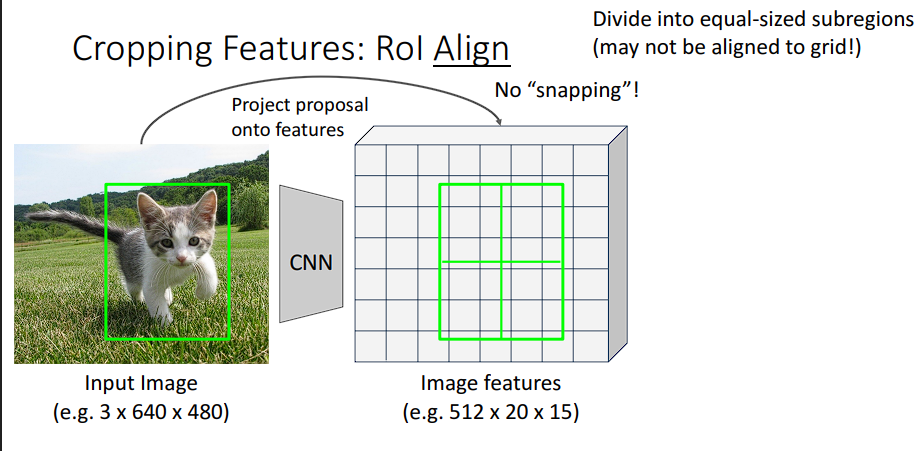
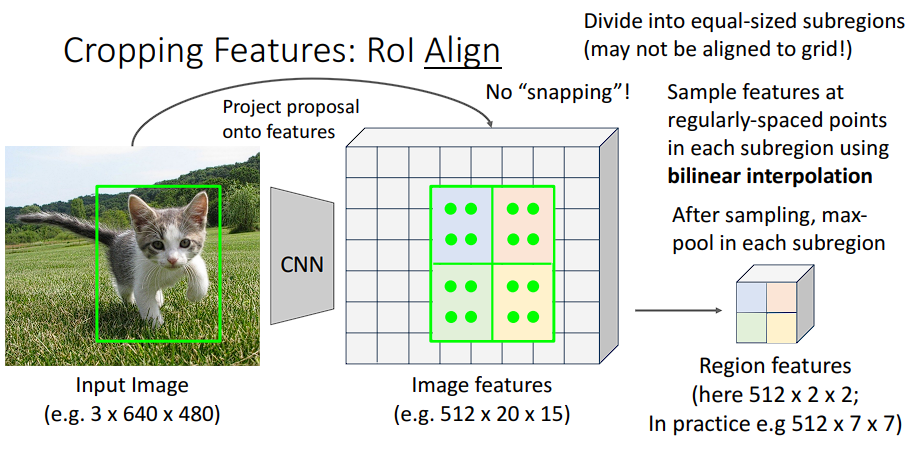
解决办法是使用RoI Align,废除取整,改用双线性插值:在小数坐标位置用周围4个像素加权计算,精度更高。
性能对比
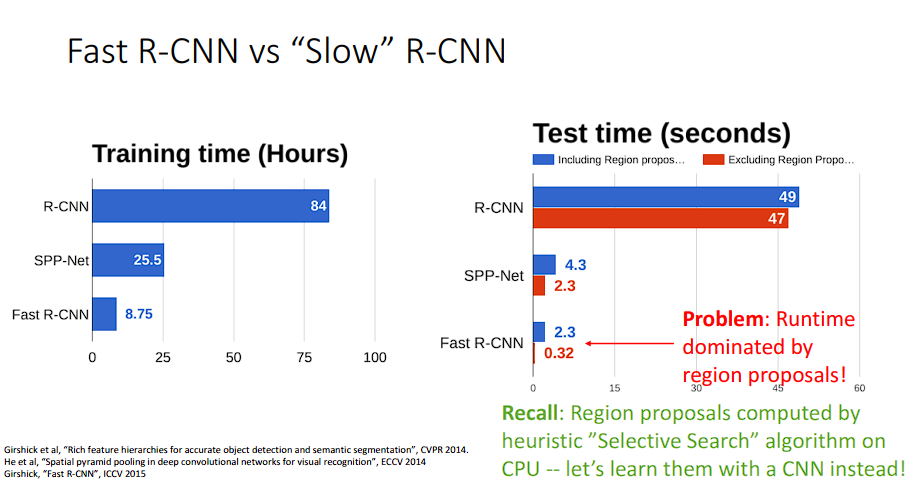
可以看到,Fast R-CNN的训练测试时间更短,但是其时间瓶颈还是在“区域推荐”这里,所以,一个很好的办法是使用CNN去学习推荐的区域,这样就可以把时间缩短至更少。
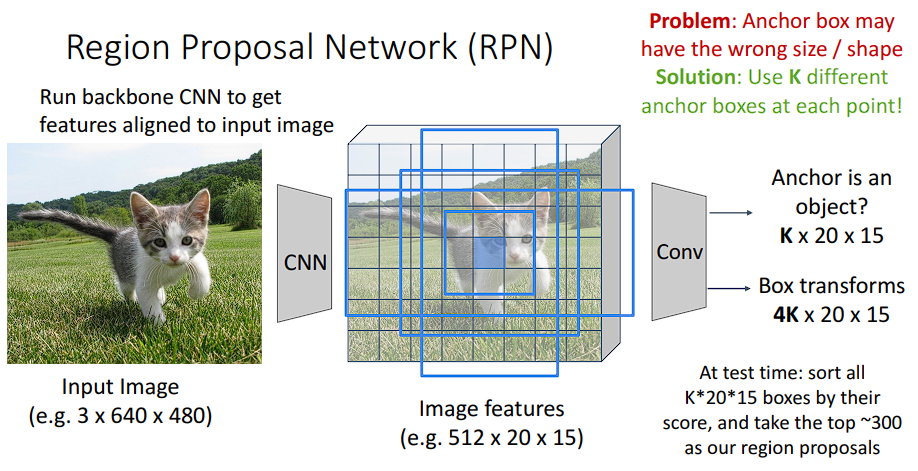
RPN网络
用一个小型卷积网络在特征图上扫描,自动生成候选框,具体思路如下:
-
在每个位置预设“标准检测框”(
Anchor)在特征图的每个像素位置,生成
k个不同大小的参考框1 2 3 4 5 6 7 8 9# 在一个特征图位置上 anchors = [ (128×128), # 小正方形 (256×256), # 中正方形 (512×512), # 大正方形 (128×256), # 瘦高 (256×128), # 矮胖 ... ] # 共9个确保能够匹配各种尺寸的目标
-
滑动窗口扫描并打分
使用一个
3x3x512的卷积核在特征图上滑动,对每个位置的k个框做两件事:1 2 3 4 5 6# 输入:特征图上3×3×512的小区域 # 输出1:分类分数(2k个值)→ 每个锚框是前景/背景的分数 # 输出2:回归修正(4k个值)→ 每个锚框的Δx, Δy, Δw, Δh cls_score = conv_cls(sliding_window) # 形状: [H×W×k, 2] bbox_pred = conv_reg(sliding_window) # 形状: [H×W×k, 4]分类分数:判断这个框里面有没有物体
回归分支:如果有物体,调整框的大小和位置,让他更加贴合目标
-
生成候选框
- 平移+缩放:用回归修正量调整锚框位置
最终框 = 锚框 + 网络预测的Δx, Δy, Δw, Δh - 排序过滤:按前景分数排序,用NMS去重,保留Top-N(如2000个)作为候选框
- 平移+缩放:用回归修正量调整锚框位置
至此,我们已经说明了目标检测的一个基本思路,现在我们来看看一阶段检测器和二阶段检测器
一阶段和二阶段检测器
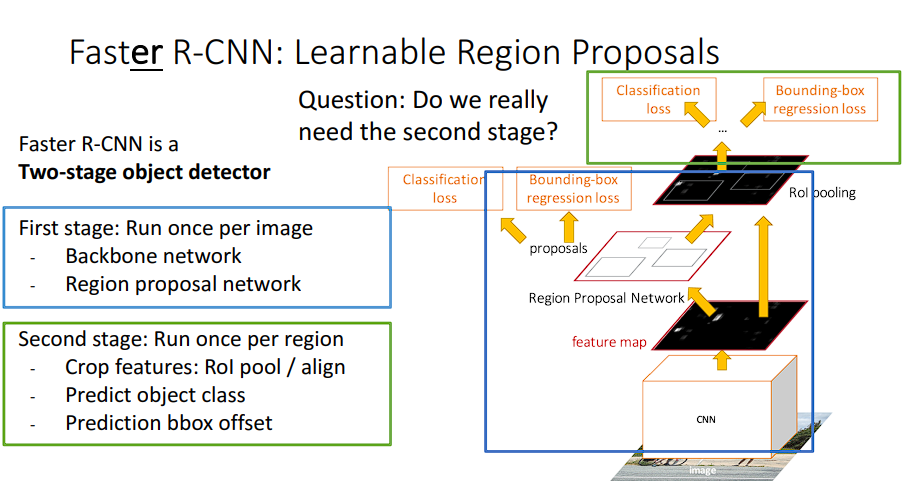
上图说明了一阶段和二阶段检测器的区别。对于一阶段来说,其流程:输入图像 → Backbone → 直接输出密集预测 → NMS → 最终框+类别,其思路是:
- 在特征图的每个位置预设锚点
- 直接预测每个锚框的类别概率和位置修正量
- 无需单独的候选框生成
One-stage:在特征图每个位置对预设的k个anchor直接做分类回归;Two-stage:先用RPN **生成候选框 **,再对候选区域精细分类回归。
总结
目标检测是计算机视觉的一个重要的研究,例如像大名鼎鼎的YOLO系列,下次来看看更多的研究吧!