前言
在上一篇文章中,我们描述记录了RNN的基本结构,让我们快速回顾一下。
首先,RNN是为了能够处理序列问题而发明出来的。对于之前学习的CNN来说,一个重要的特征是CNN可以提取相似的特征,对于同一个特征,它门的向量很相似。但是,对于语言来说,比如说“it”这个单词会因在上下文中的位置而有着不同的涵义,如果只是简单的提取特征则不会有这种理解上下文的智慧。因此,RNN应运而生,其思路就是当前网络的输出不仅与当前的输入有关,还与前一时刻网络的输出有关。更详细来说,我们把网络的输出叫做隐藏层h,可以写出这样一个式子:$h_t = f(h_{t-1}, x_t)$这样就可以很好的解决“记忆”这个问题。
但是,因为在反向传播的时候需要用到链式法则,所以当网络变得很深时,就容易出现梯度消失或者梯度爆炸这个问题,而一般来说,网络越深,那么其结果也就越好。所以为了解决这个问题,也就引入了LSTM,即长短期记忆网络,我们来看看LSTM是怎么解决这个问题的。
LSTM
LSTM的结构
LSTM依然保留了RNN的基本结构,即接受一个输入x_t和一个隐藏层输出h_t-1,不同的是,它把原来RNN的简单更新状态使用门技巧给取代了。
处理接受x_t和h_t-1之外,LSTM还需要接收一个cell状态,暂且叫他cell吧,不翻译作细胞了。除此之外,还有门结构,分别是
input gateforget gateoutput gateblock gate
下面来说一下其计算方式。
LSTM组件的计算方式
得到变量门
第一步计算一个$a$,即$$ a = W_xx_t + W_hh_{t-1} + b $$,这一步和计算RNN的隐藏层一致,不过$a$是我们得到上面四个门的必要条件。有了$a$,我们就可以计算四个门的值
即
- $ i = \sigma(a_i) $
- $f = \sigma(a_f)$
- $o = \sigma(a_o)$
- $g = tanh(a_g)$
我们需要把$a$拆分为4个门,比如,a是一个(N, 4H)的矩阵,那么i,f,o,g就是(N, H)的矩阵。而$\sigma$就是sigmoid函数。
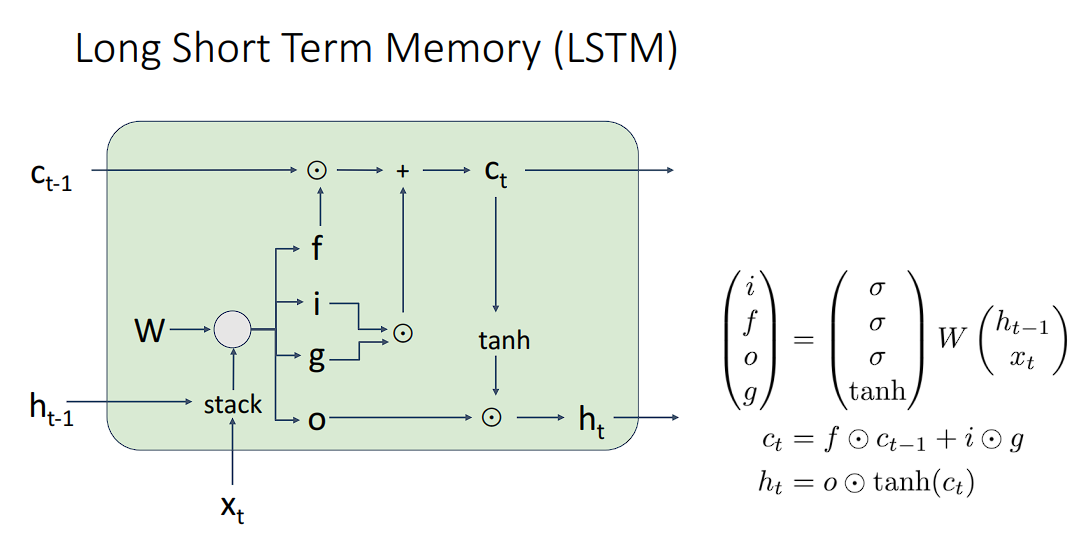
计算cell值
我们使用cell值去更新隐藏层h的状态,cell层的计算过程是
$c_t = f \odot c_{t-1} + i \odot g$, 得到c_t之后,就可以正常的去更新隐藏层的状态了
$ h_t = o \odot tanh(c_t) $,注意,$\odot $是点积的意思。
之后的计算部分和RNN没有什么区别,下面我们重点来看一看attention的内容。
Attention LSTM
在讲attention之前,我们先来看一看attention解决了哪些问题。
seq2seq
在上文中我们提到,rnn可以去解决那些:
- 多对一问题,例如文本情感分析
- 一对多问题,例如图片描述
- 多对多问题,机器翻译
我们就以多对多问题出发。首先,在多对多问题中有两个常见的助手,分别是encoder和decoder,我们可以理解为一个压缩原始信息和从压缩后的信息去解码的两个网络。而机器翻译的流程一般是这样的:
encoder网络对输入进行编码- 输入编码后得到一个长向量,一般把这个向量叫做
context,即上下文 decoder网络对上下文向量进行解码,得到输出。
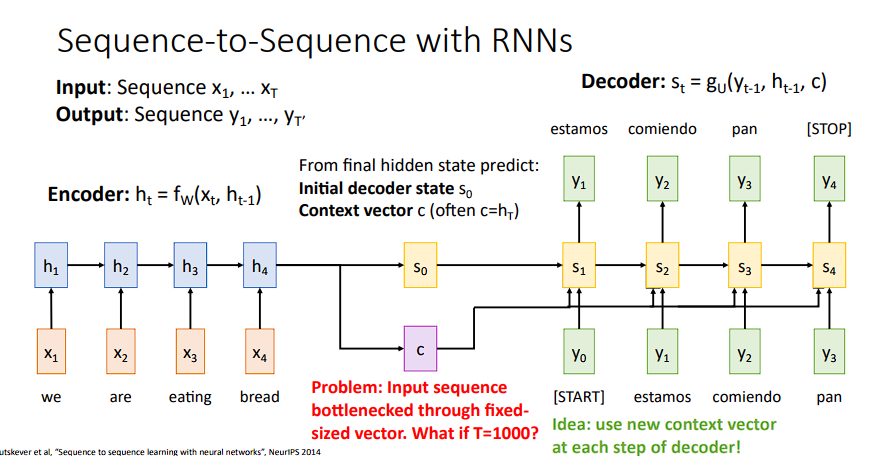
这样做的确可以解决一些问题,缺点就是:
- 当序列很长时,固定维度(例如512维的向量)的向量不能很好的理解上下文
- 不能动态的关注某一个词在上下文中位置
其实这两个问题都是context上下文过短导致的,也就导致我们不能很好的去处理对应的词汇。
就好比让你读一边书记住后再去考试,记忆力是有限的
而Attention可以解决这个问题。
Attention机制
Attention可以理解为评分决策,即在每次使用decoder解码时,不再去使用“静态的”上下文,而是去根据当前词汇去动态的更新context
我们来说一下具体的计算方式
-
将
decoder的初始状态S0与之前每个时间步t的隐藏层作运算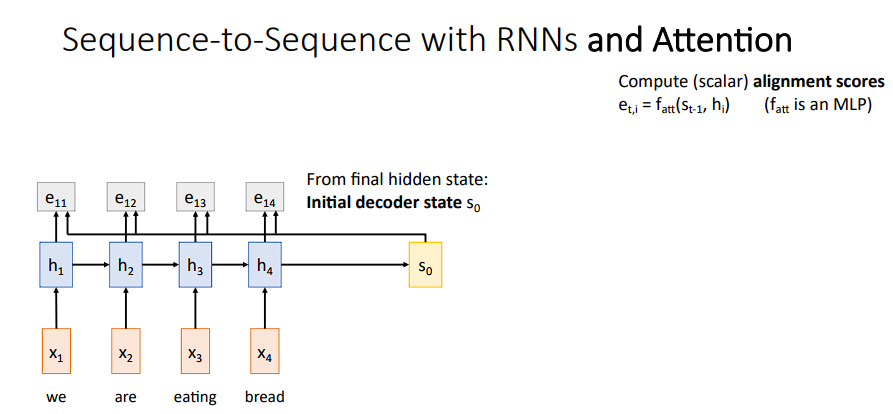
S0其实就是最后一个隐藏层,与每个隐藏层作运算后得到e11,e12,e13,e14,然后再对结果进行softmax变换得到对应的概率分布(a11,a12,a13,a14)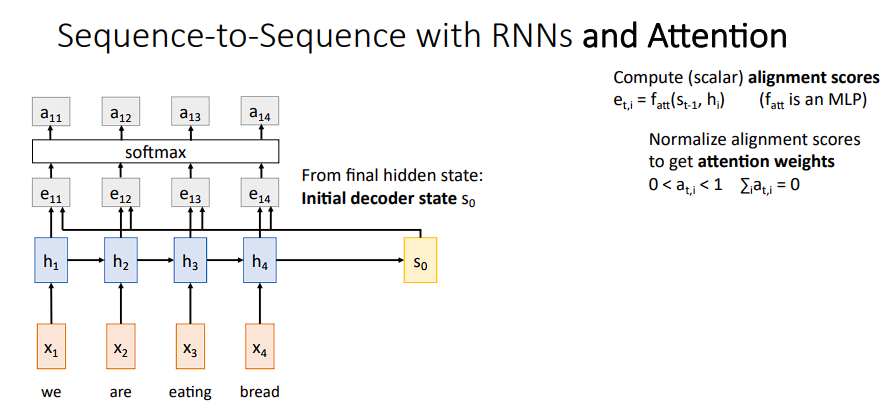
其中,
a11就是h1层在第一个上下文中的权重参数,以此类推,我们将每个隐藏层与其对应权重相乘相加,就可以得到一个上下文c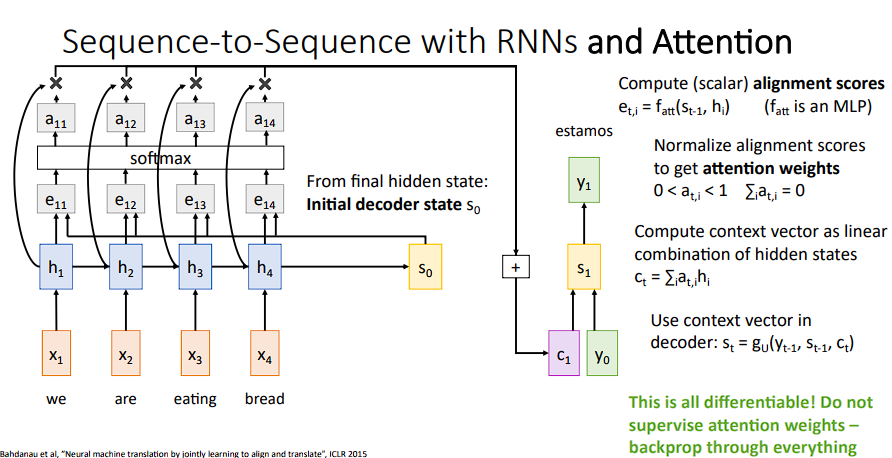
-
得到上下文
c1后,decoder的解码策略还是根据所获得的上下文去进行解码,与之前相同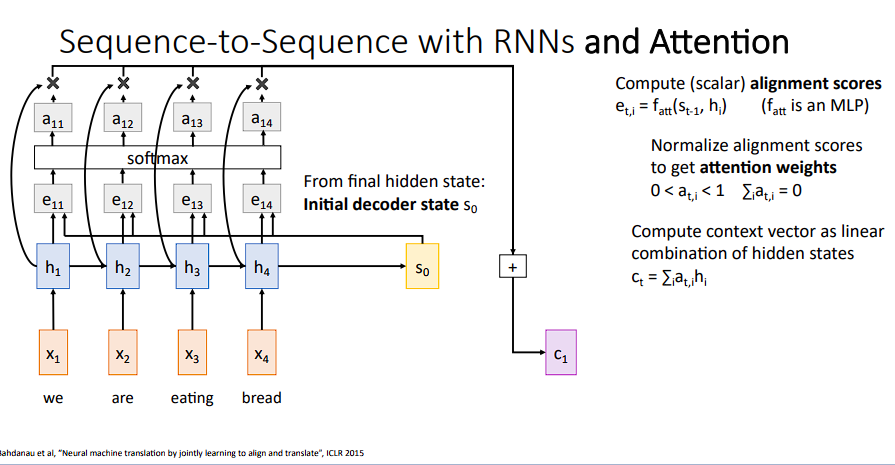
-
根据
y0, s0, c1,可以计算出s1(注意,decoder网络的隐藏层使用s来进行表示)计算出
s1之后,继续重复之前的“打分操作”,可以得到新的注意力权重(a21,a22,a23,a24):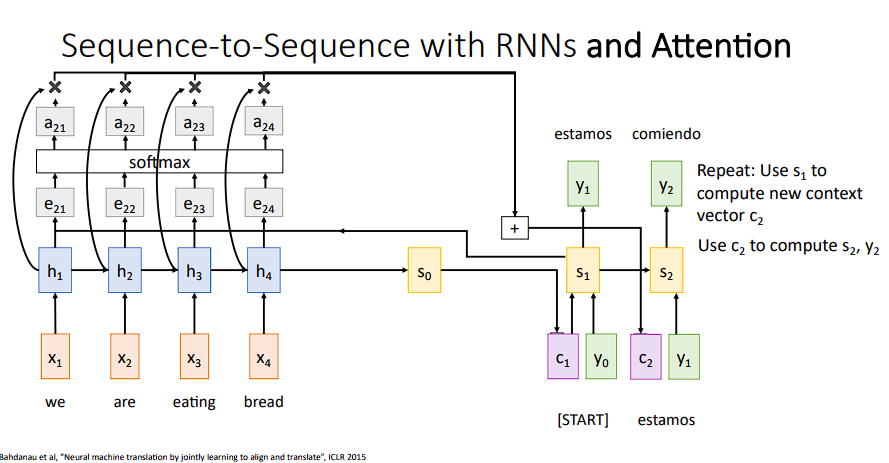
-
最后,我们可以得到最后的完整输出
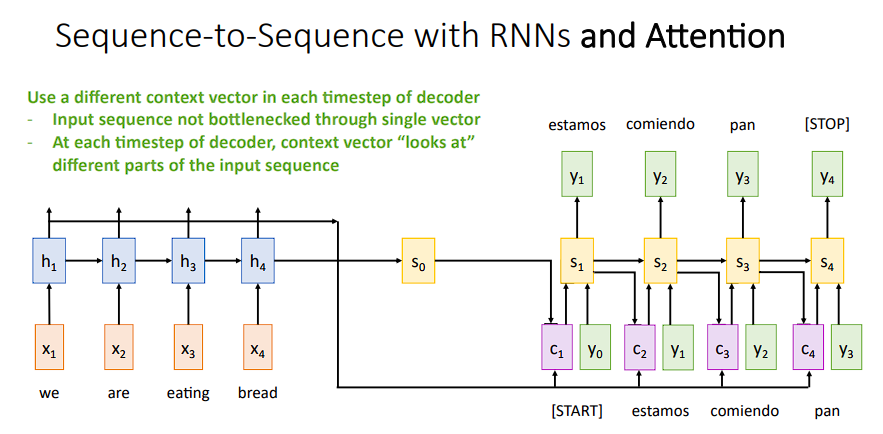
Attention推广
更一般的,我们可以把上面这个流程进行推广
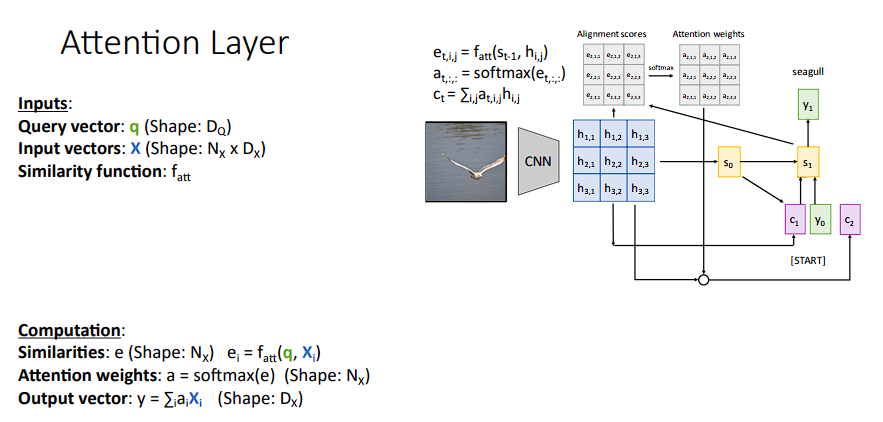
我们来看看其计算流程:
-
将
Query Vector与Input Vector作相似度计算这个过程很像
decoder的s和encoder隐藏层作计算的形式,总之,我们的目的就是去得到attention的权重参数。 -
将得分进行
softmax -
得到输出
vector
相似度计算
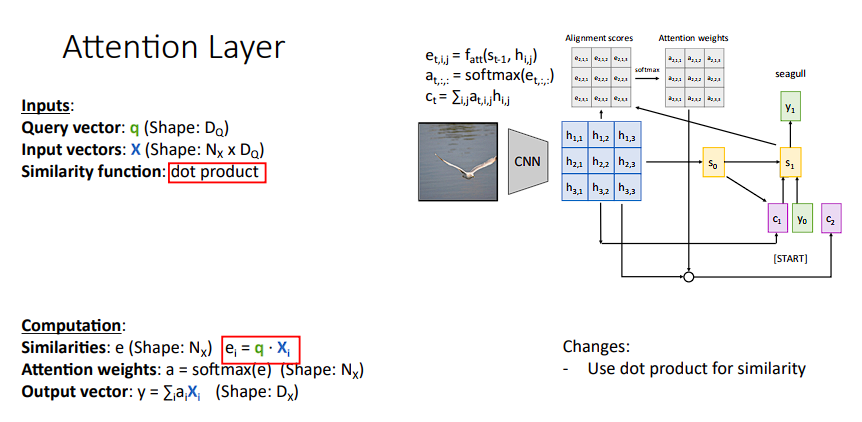
相似度计算即f_attn函数,这里提供了点积相似度和缩放点积相似度
-
点积相似度
-
缩放点积相似度
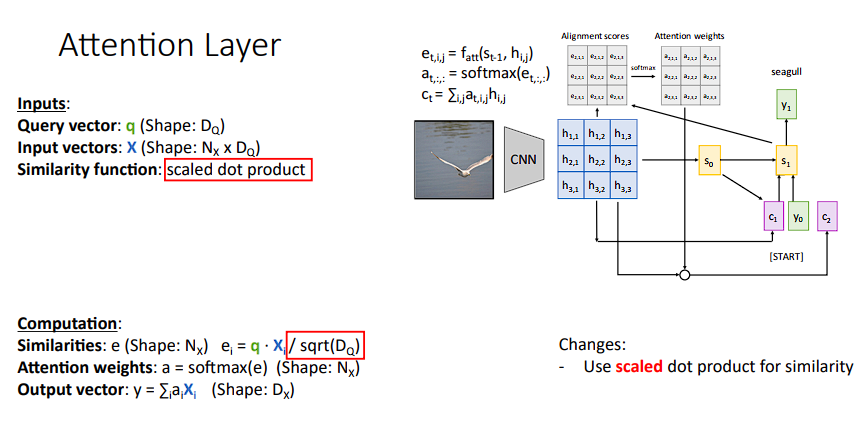
我们现在来看看有多个query vector时的情况:
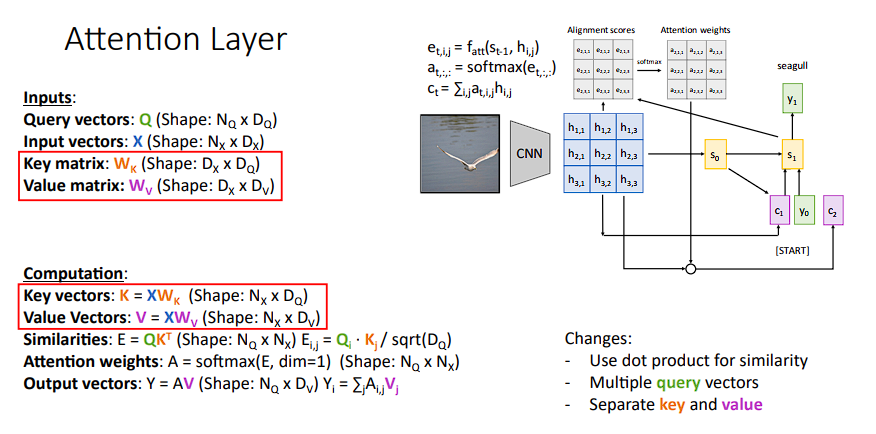
现在情况有些复杂,我们来一步步的拆开说明其计算步骤
-
当前的
query vector已经转变为Query vectors向量 -
我们专门设置两个额外的变量,即
K和V,K和V都是输入X在不同空间的投影,所以可以这样理解:- 哪些维度适合“匹配”
(K) - 哪些维度适合“被提取”
(V)
即
- 用
Q去匹配K(找相关内容) - 得到权重
- 用权重去取
V(真正的信息)
- 哪些维度适合“匹配”
课堂上举了一个例子:就像是你去Google上搜索“帝国大厦有多高”,Google会返回给你一个网页标题和里面的内容,内容里面说明了帝国大厦的高度,但是你已经知道标题了(就是我们搜索的内容),所以你只需要拿到内容的值即可
所以其计算结果可以这样表示:
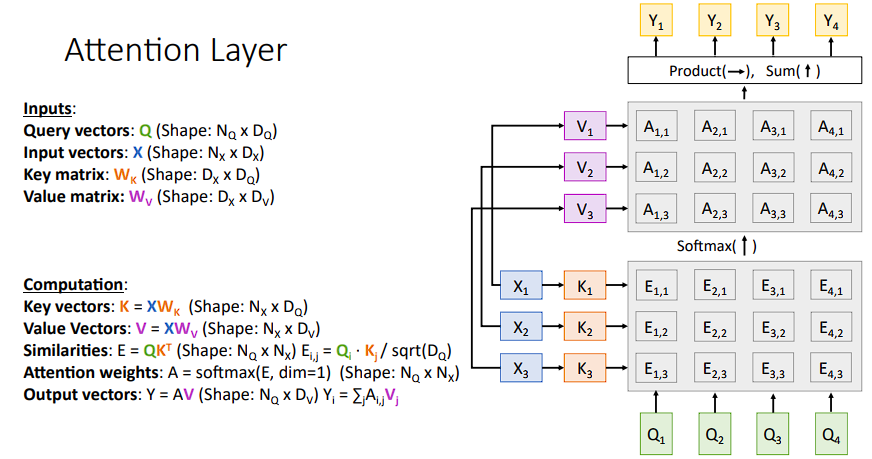
- 抽取
X的特征,得到K($X K ^T$) - 将
K和Query作相似度计算,softmax后得到A,即特征的分数 - 抽取
X输出值的特征,得到V($XV$) - 将
A和V作点积运算求和后得到最后的输出
self-attention机制
self-attention的计算与上面我们提到的计算不同在于Q的计算来源
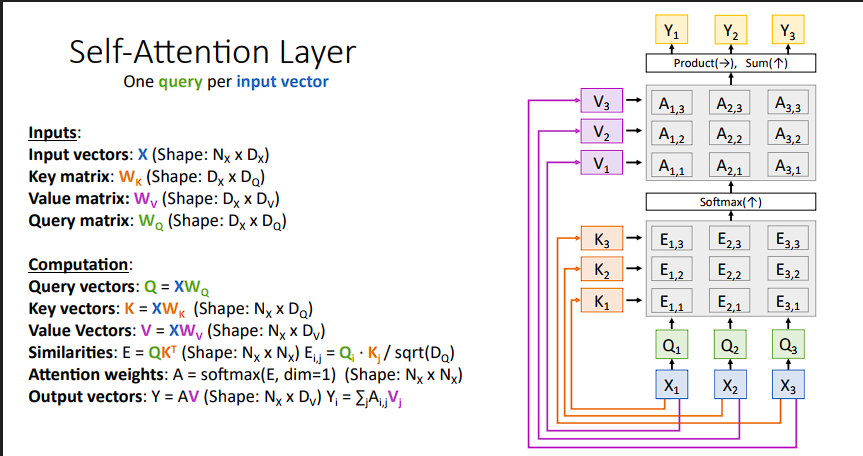
在self-attention的计算中,只有输入X是给定的,其它部分都需要我们自己去计算,包括
Q: $ XW_Q$K:$XW_K$V:$XW_V$
其余部分也跟计算上面attention的一致。
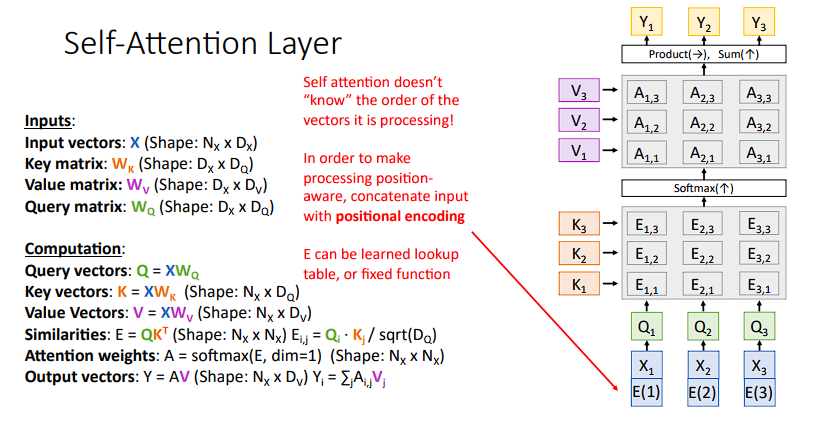
Tips: 在计算过程中,如果改变输入的顺序,比如改成
X3,X1,X2,那么网络的输出结果也会随之发生变化,变成Y3,Y1,Y2,也就是说对输入顺序并不敏感,为了加强顺序的影响,我们可以加一个位置编码
Masked self attention
Masked self attention的思路就是说,对于现在的self attention,每个单词之间都是互相可见的,而之前的RNN则是需要根据前一时刻的输出来确定当前时刻,所以,为了控制信息的可见范围,我们引入了Masked矩阵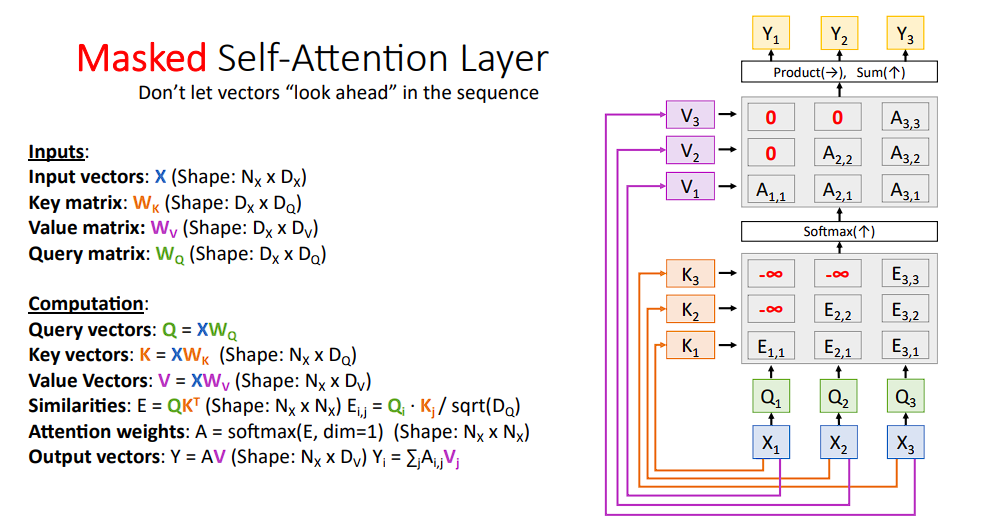
在得到Q和K后,使用一个下三角矩阵,经softmax之后,$-\infty$就变为了$0$,这样就限制了单词能够查看的范围,更加便于训练。
多头注意力
多头注意力机制也是经常能够听到的词语了,多头注意力机制Multi-head的样子大概长这样

对于输入来说,我们这次使用多个注意力块来提取其中的信息,其优点在于**Multi-head attention 是对同一输入,通过多组不同的线性变换映射到不同子空间,在每个子空间中分别进行 attention,从而捕捉不同的关系,最后将结果拼接起来。**也就是说,每个attention块的关注点不同,其捕获到的信息也就越多。
各种结构的比较
目前我们学习了三种网络,按照时间顺序来排列的话,包括
CNN,卷积神经网络RNN,循环神经网络attention,注意力机制
其优缺点如下图:
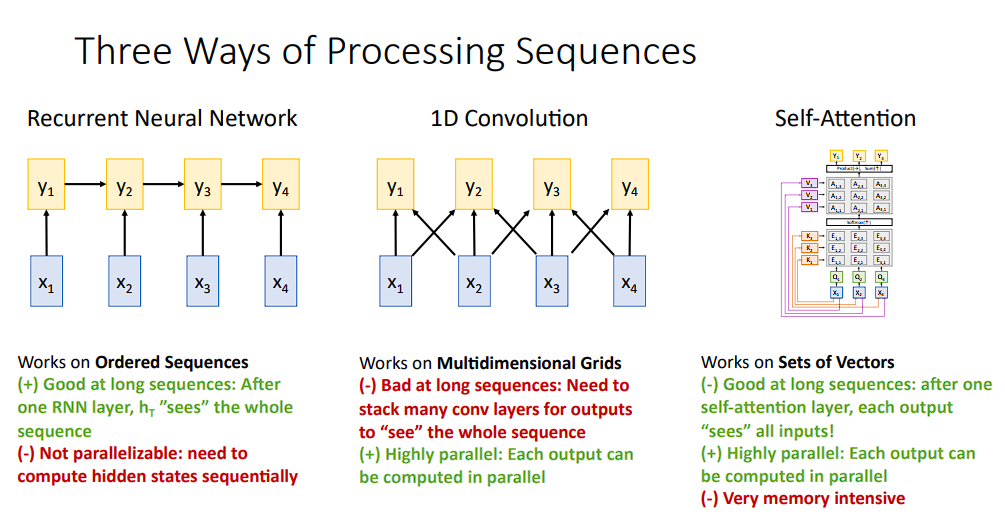
- 循环神经网络可以很好的处理序列问题,并且可以得到一个关于整个序列的“映像”,但它不能很好的并行运行,也就无法使用专有硬件进行加速
- 卷积神经网络不擅长处理长序列问题,但却可以并行计算
- 而自注意力机制可以很好的处理序列问题,也可以很好的并行化,缺点是需要占用大量内存
总结
这次实验需要的知识还是很多的,有的甚至都没见过,为了不让篇幅过长,Transformer留着下次再说!