前言
这次来学习一下一个之前从未接触到的网络架构RNN,来看看RNN解决了哪些CNN不好解决的问题。
RNN
过去的问题
我们之前解决的问题,一般是网络接收一个输入,比如说某张图片,需要正确给出这张图片的类别,也就是分类问题

但是,还有许多问题不是离散的输入,比如说“一句话”或者“一段声音”,以ppt中为例
-
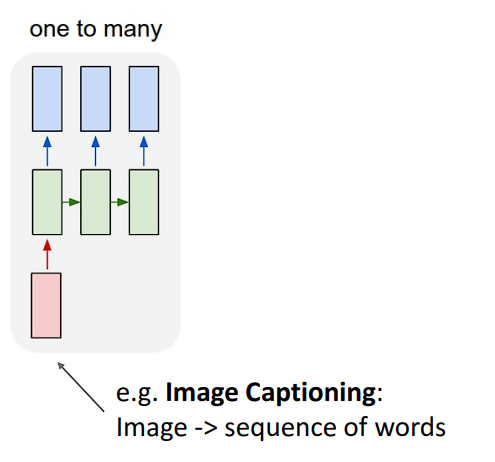
一对多问题
一个典型的例子是:输入一张图片,用一句话输出图片的内容,也就是Image Captioning。
-
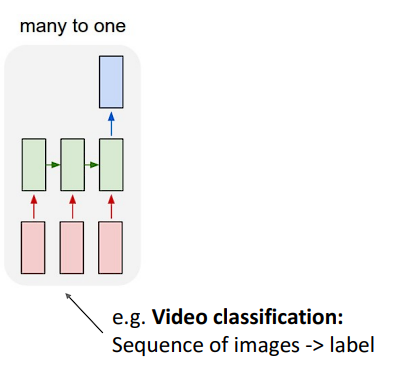
多对一问题
输入是一段序列,输出是一个类别,例如视频分类
-
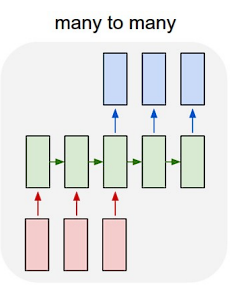
多对多问题
输入和输出都是一段序列,例如常见的机器翻译
RNN的结构
RNN解决的是一个序列问题,为了让网络理解这个序列问题,一个关键的思路是使用一种“中间”状态,当序列不断输入时,这个中间状态也一直在更新。
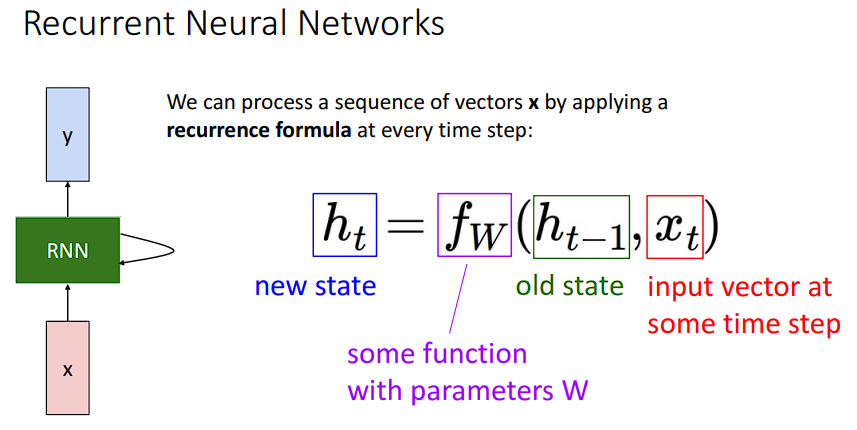
也就是说,当前时刻的中间状态(隐藏层)$h_t$由$h_{t-1}$和$x_t$共同决定,$x_t$是我们的输入,例如一个词向量。
下面是一张更为清晰的RNN计算输入输出的过程:

这样的RNN也被叫做Vanilla RNN。
RNN的计算图
在本门课程的lab中,大多需要手动推导计算forward和backword,因此,了解RNN的计算过程可以很好的帮助我们理解前向传播和计算反向传播的过程。
首先,RNN接收一个初始的隐藏层,我们叫做h0,除此之外还接收一个输入x1,大概如下
|
|
也就是说,每一个时间步,都会有一个根据x1和h_prev得到的h_next。最后的计算结果图如下
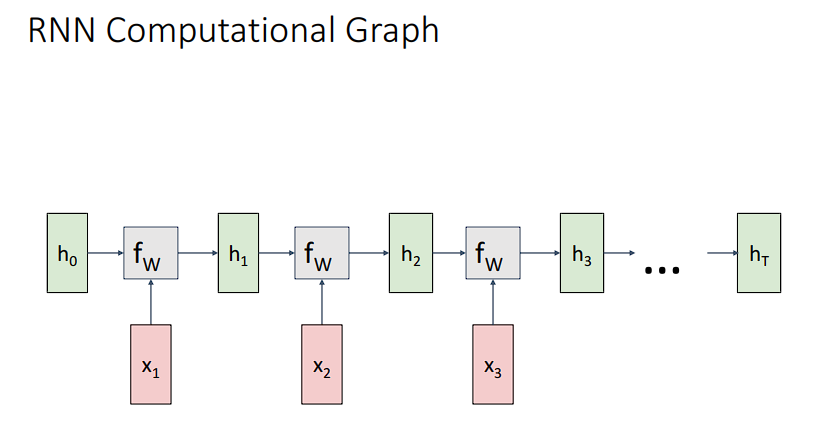
需要注意的是,在整个的计算过程中,每一步时间T所使用的权重矩阵W都是一致的,使用同一个矩阵W一下子生成可能会更好的联系和把握上下文。
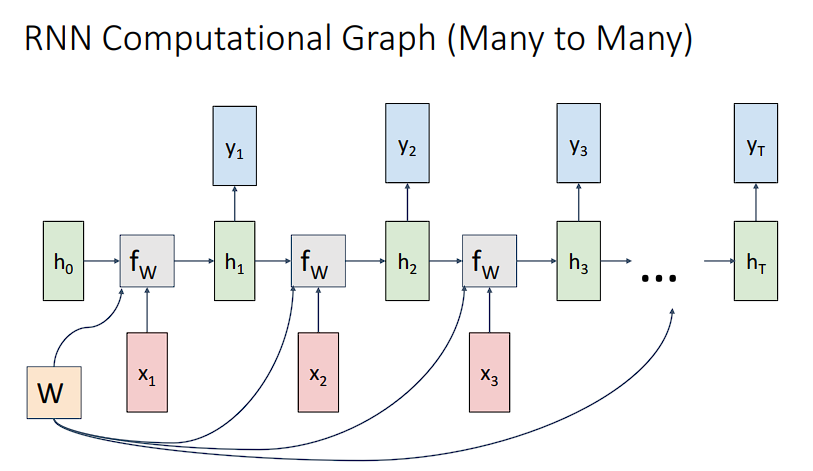
课堂上老师还记录了许多不同类型的输入输出的计算过程,这里不一一展开说明了。
Image Captioning
有了上述基础,我们就可以来看看课堂上举的这个例子了。
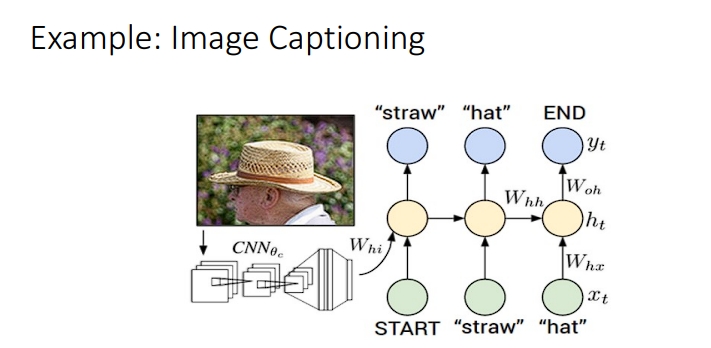
这个例子的想要做到的效果是,输入一张图片,网络可以根据这张图片来描述一下当前输入图片的内容。
这个问题就是我们上面说的Many To One 的例子,也就是说,其处理流程如下
- 首先,我们使用
CNN来获取图片的特征 - 使用某种方法,可以把图片转换为
RNN可以理解的样子,也就是初始的h0 - 这个时候需要有一个输入
x,也就是<START>标签。 - 最后得到所有的输出
实验
本次的实验要求是使用RNN和LSTM去完成课上提到的"描述图片内容"的任务,下面来记录一下使用RNN完成该例子的过程。
COCO数据集
对于本次实验使用的是2014年发布的COCO数据集,该数据集已经成为Image caption的标准测试。这个数据集包含了80,000张训练数据和40,000张验证数据,每张图片都有5个字幕。实验之前,COCO数据集已经被经过下采样处理过了,每张图片的大小是112x112的。这次实现中将会使用RegNet-X 400MF的网络去抽取图片特征。
还有一些额外的提示:直接处理字符串是低效的,所以我们将用一个编码后的字幕去进行实验。每个词都分配了一个整数ID,这样我们就可以使用整数ID去代表一个词。
实验
也就是说,我们现在有:
- 处理好的图片
- ID和词映射
现在来说明输出单词的格式。
这里有几个特殊的生成Token
<START>:开始Token,出现在句子开头<END>:结束Token,出现在句子结尾<UNK>:出现频率很低的词<NULL>:作为占位符去补充字幕,方便计算
数据详情
经过上面这些处理后,可以将图片进行可视化


单步RNN
RNN forward
首先是实现单步的RNN,也就是rnn_step_forward。先跟着思路慢慢来,下面是code中的提示,我们只看有用的部分
|
|
这个其实很好计算,ppt上的公式如下
结果求出next_h即可,就是简单的套公式就行。
RNN backward
反向传播只需要记住链式求导法则即可,首先,函数参数中给了我们上游梯度dnext_h,也就是损失函数对与next_h的参数,我们可以来推导一下这个计算过程。
在之前的问题中,可以理解为y = Wx * x + b,通常来说,我们只需要求得
Wx的梯度和b的梯度即可。而这里求x的梯度,我觉得可以这样思考,因为对之前的输入x,其值都是确定的,也就是说,这里的x很有可能来自前一个网络的输出,
对于$x$来说,
$$ \frac{\partial L}{\partial x} = \frac{\partial L}{\partial next_h} \times \frac{\partial next_h}{\partial x}$$
而$ \frac{\partial L}{\partial next_h} $$就是上游梯度$$ \mathrm {dnext_h} $,所以我们可以推导出
$$\mathrm{dx} = \mathrm{dnext_h} \times \frac{\partial next_h}{\partial x}$$
ht计算公式
$$ h_t = tanh(W_{hh}h_{t-1} + W_{xh}x_t) $$
所以$ \frac{\partial{next_h}}{\partial{x}} $ 需要使用符合函数求导,即为$$\mathrm{da} = 1 - h_{t}^2 $$所以,$$ \frac{\partial{next_h}}{\partial{x}} = \mathrm{da} \times W_{xh}$$
同理,$$ \frac{\partial{next_h}}{\partial{W_{xh}}} = \mathrm{da} \times x_t $$
$$ \frac{\partial{next_h}}{\partial{W_{hh}}} = \mathrm{da} \times h_{t-1} $$
计算方式如上,不要忘记与$\mathrm{dnext_h} $相乘!
连续时间片
现在,我们有了单步的前向传播和反向传播,这个时候就可以去在连续的时间片上进行传播。
前向传播
这是代码的注释
|
|
我们重点来看看参数的含义。
首先输入是NxTxD的类型,也就是说,我们只需要在T时间步上,每一次都进行step_forward即可。同时,把每一时间片的隐藏状态保存下来。要注意计算过程中的矩阵维度问题
反向传播
现在来看看反向传播的过程,先贴一张图
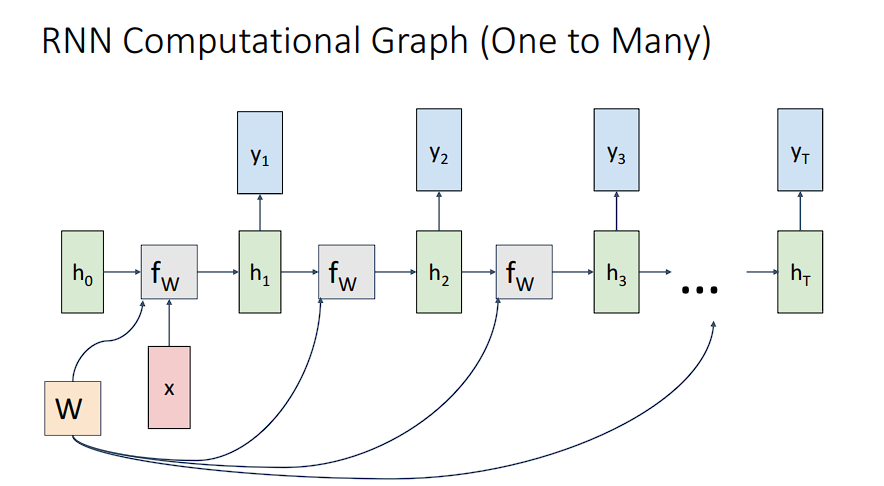
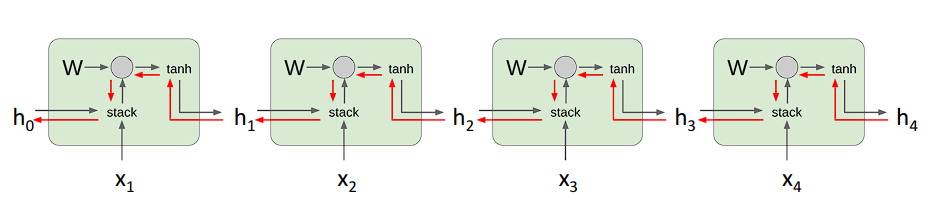
对于t时刻的梯度来说,比如图中的h2,因为整个时间片t是使用一个权重参数,所以梯度在每一个时间片也是跟前后时间有关的。
其实我们只需要关注梯度的流向即可,对于h2来说,一部分直接流向了输出,比如说是y2,另一部分直接流向了h3,而h3又流向了h4,所以,就h2而言,其梯度的值为当前梯度值和上游梯度值,所以这其实是一个累加的过程。
在求梯度时,我们需要注意每一层梯度之间的累加,对于最后一个隐藏层来说,其没有上游梯度,所以求解的时候要倒着去遍历时间片。
词嵌入
到目前为止,我们有
- 采集数据集图片特征的网络
- 图片处理后的字幕
- 完整的
RNN结构
对于深度学习中,词语一般是由一个D维向量来表示的,这里先记住这个结论,不要在意细节。也就是说,我们可以找到一个词汇表,其维度是(V, D)的,有V个词,每个都是一个D维向量。
值得注意的是,词向量是学习过来的。首先,我们有word_to_idx,类似于
|
|
这类的东西。
当我们想要输入cat这个词,就会去调用word_to_idx['cat'],得到索引是0,然后再去调用embedding,得到词向量embedding[0],也就拿到了我们的输入。
计算loss
我们选择的损失函数是交叉熵损失函数,实验中对损失函数的描述如下
|
|
看一看参数的描述
-
x: We assume that we are making predictions over a vocabulary of size V for each timestep of a timeseries of length T, over a minibatch of size N.
N个数据,对于每个时间步T,都有模型预测出的V个词分数。比如
1 2 3 4 5[ [0.8, 0.9, 0.7], # 第一个时间步,T1,分数最大索引是2 [0.7, 0.2, 0.1], # 第二个时间步, T2,分数最大时1 ... # 以此类推 ]这样,我们就可以获得分数最大的那个词的索引,从而获得对应的词。
-
y:Ground-truth indices, of shape (N, T) where each element is in the range 0 <= y[i, t] < V
这个好理解,对于每个时间步,都有一个正确的答案,比如
1 2 3 4[ 2, 3, ]
F.cross_entropy(input, target) 要求:
输入:
input: shape = (batch_size, num_classes)target: shape = (batch_size,) 每个位置是一个类别 index
这样就把连续的N个问题分为了N*T个离散的分类问题
开始实验
到目前,我们的所有准备工作已经做完了,可以开始做实验了。
数据处理
在CaptioningRNN中,我们还需要对图片进行一些线性层变换。
首先我们需要对图片进行编码,把它变成RNN认识的样子,也就是调用提供的ImageEncoder类
在COCO数据集中,输入的image的形状是(2, 3, 112, 112)的,经过采样后变成了(2, 400, 4, 4)的,其中,400就是输入维度,此时,输入的图片特征为(N, D, 4, 4),我们需要把这个图片转为(N, H)的,也就是RNN可以理解的格式,我们可以采取以下的变换
|
|
我们还需要将隐藏层和词嵌入层联系起来,所以我们还得需要一个转换
|
|
然后就可以考虑前向传播的逻辑了。
前向传播
-
抽取图片特征为
RNN可以看懂的形式1 2features = self.image_encoder(images) features = self.feature_projection.forward(features) # h0得到了
h0 -
转换字幕为词嵌入的形式
这里我们只是做了简单的转换,并未开始训练。
1word_embed = self.word_embedding.forward(captions_in) -
使用
RNN,生成每个时间T的隐藏层1hn = self.RNN.forward(word_embed, features) # 每个隐藏层的输出 -
计算得分
1scores = self.output_projection.forward(hn) -
计算
loss1loss = temporal_softmax_loss(scores, captions_out, ignore_index= self.ignore_index)
训练阶段和测试阶段是两个完全不同的结果,我们来看看测试阶段是怎么进行处理的。
测试阶段
在测试阶段,应该是:
- 给
RNN一张可以理解的图片作为初始h0 - 给
RNN一个初始输入词,比如<START>标签
在每一个隐藏层上,需要找出隐藏层对应的最大得分索引,然后再去找到对应的词。
这是几张测试效果图:


总结
其实整个过程还是很复杂的,尤其是对于初次学习的同学来说,下次我们将看看LSTM部分的实验!